Executive Summary
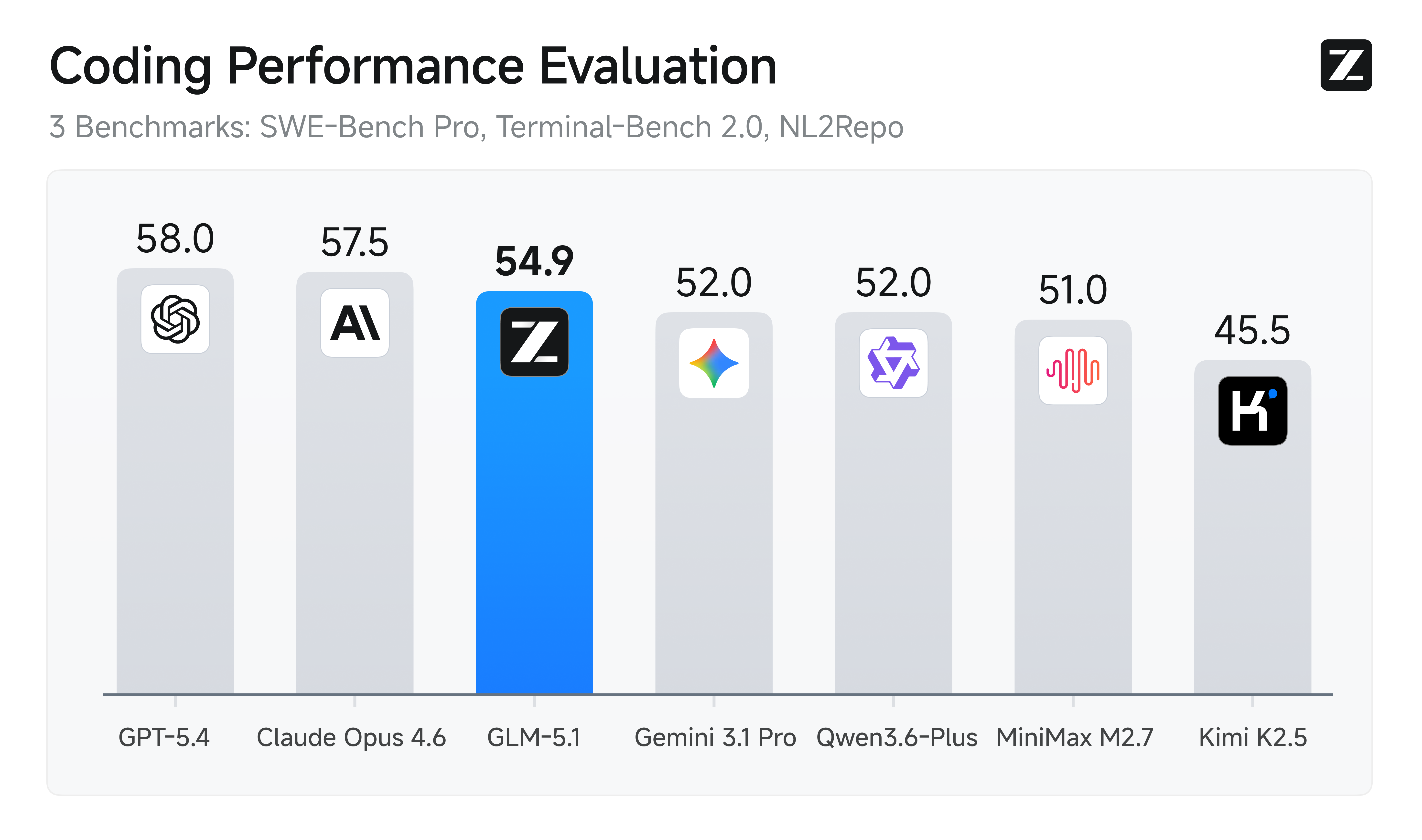
GLM-5.1 by Zhipu AI just became the first open-source model to beat both GPT-5.4 (57.7%) and Claude Opus 4.6 (57.3%) on SWE-Bench Pro, scoring 58.4%. Released April 7, 2026 under the MIT license — the most permissive open-source license available.
The MIT license is more valuable than benchmark scores for enterprise deployment. It enables full self-hosting with zero data residency restrictions.
What It Is
GLM-5.1 is a 754B parameter Mixture-of-Experts (MoE) model with 40B active parameters per forward pass. Built on the GLM_MOE_DSA architecture combining Gated DeltaNet linear attention with DeepSeek Sparse Attention.
| Specification | Value |
|---|---|
| Total Parameters | 754B (744B MoE + shared) |
| Active Parameters | 40B per token (8 routed + 1 shared expert) |
| Context Window | 200,000 tokens |
| Maximum Output | 131,000 tokens |
| Training Tokens | 28.5 trillion |
| Training Hardware | ~100,000 Huawei Ascend 910B chips |
| License | MIT (fully open source, commercial use allowed) |
| HuggingFace Downloads | 124,162 |
Architecture Innovation: DeepSeek Sparse Attention
- Lightning Indexer: Scores prior tokens to identify which are worth attending to
- Selector: Keeps only a smaller subset for attention
- Reduces training/inference costs while maintaining long-context fidelity
Benchmarks: The Numbers That Matter
| Benchmark | GLM-5.1 | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro | 58.4% (1st) | 57.7% | 57.3% | 54.2% |
| NL2Repo | 42.7% (1st) | 41.3% | 33.4% | - |
| CyberGym | 68.7% (1st) | - | 66.6% | - |
| GPQA-Diamond | 86.2% | 92.0% | 94.3% (1st) | - |
| AIME 2026 | 95.3% | 98.7% (1st) | 98.2% | - |
Why SWE-Bench Pro Matters
SWE-Bench Pro evaluates real software engineering tasks:
- Applying patches to real GitHub repositories
- Fixing bugs with natural language descriptions
- Implementing features from issue descriptions
Critical distinction: Passing test suites != solving underlying bugs. Agent scaffolds can swing results by 22 points. Eval methodology matters enormously.
The 8-Hour Achievement: Long-Horizon Execution
GLM-5.1's defining capability is sustained autonomous execution for up to 8 hours. Z.ai demonstrated:
VectorDBBench Optimization (600+ Iterations)
- Previous SOTA: Claude Opus 4.6 achieved 3,547 QPS
- GLM-5.1 ran 655 iterations with 6,000+ tool calls
- Final result: 21.5K QPS — 6x improvement over single-session results
"The longer it runs, the better the result."
Cost Comparison: The Real Economics
| Model | Input ($/1M tokens) | Output ($/1M tokens) | Self-Hosting |
|---|---|---|---|
| GLM-5.1 | $1.40 | $4.40 | Yes (MIT) |
| Claude Opus 4.6 | $15.00 | $75.00 | No |
| GPT-5.4 | $10.00 | $30.00 | No |
| DeepSeek V3.1 | $0.56 | $0.56 | Yes |
GLM-5.1 costs 1/10th of Claude Opus for API calls, plus self-hosting option.
Community Sentiment
From Reddit r/LocalLLaMA (+660 upvotes)
"These models are super important for when Anthropic and OpenAI decide to rug pull their coding plans." (+41 upvotes)
"GLM-5.1 is hands down the best model right now!" (+134 upvotes on r/ZaiGLM)
Skepticism from r/LangChain
"The MIT license is the actually important part. That changes deployment math for enterprises with data residency requirements." (+10 upvotes, 92% ratio)
"744B MoE with 40B active is not comparable to 100B dense in deployment cost. The 40B active parameters framing undersells routing overhead, KV cache size at 200K context."
From Hacker News
"I am using GLM 5.1 for the last two weeks as cheaper alternative to Sonnet, and it is great — probably somewhere between Sonnet and Opus. It is pretty slow though." (+47 upvotes)
Hardware Requirements: The Reality Check
| Quantization | VRAM Required | Recommended Hardware |
|---|---|---|
| Full BF16 | ~1.5 TB | 8xH100 SXM5 / 8xH200 SXM5 |
| FP8 | ~750 GB | 8xH100 |
| Q4_K_M | ~400 GB | 4xH100 |
| Q2_K | ~200 GB | 2xH100, Apple M3 Ultra |
| UD-IQ2_M (1.8-bit) | 64-128 GB | Mac Studio, single H100 |
"At 754B even NVFP4 is tight squeeze on 4x RTX 6000 PRO." — Reddit user
Why This Matters
1. Open-Source Has Closed the Gap
The era where "closed models are always better" is ending. GLM-5.1 proves open-source can match/exceed frontier models on real-world coding benchmarks.
2. Hardware Independence
GLM-5.1 was trained entirely on Huawei Ascend chips — proving US export controls cannot stop frontier model development.
3. Chinese Labs Leading Open-Source
Five Chinese labs now release world-class open-source models: DeepSeek (cost efficiency), Qwen (breadth), GLM/Z.ai (coding), Kimi/Moonshot (agentic), MiniMax (alternatives).
Sources
- Z.ai Official Blog: https://z.ai/blog/glm-5.1
- Z.ai Developer Docs: https://docs.z.ai/guides/llm/glm-5.1
- HuggingFace: https://huggingface.co/zai-org/GLM-5.1
- GitHub: https://github.com/zai-org/GLM-5
- Reddit r/LocalLLaMA (post 1sf0jok)
- Reddit r/LangChain (post 1sqllcx)
- Hacker News threads (ids 47685402, 47835229)