Most AI agents use hand-picked skills. This one grows its own.
Every agent framework right now ships with a "skills folder." You dump in some Python files, tag them with descriptions, and hope the agent picks the right one. This is fragile. When the task changes, the skills don't. A team at USTC's AlphaLab decided to fix that by making agents evolve their own.
Architecture
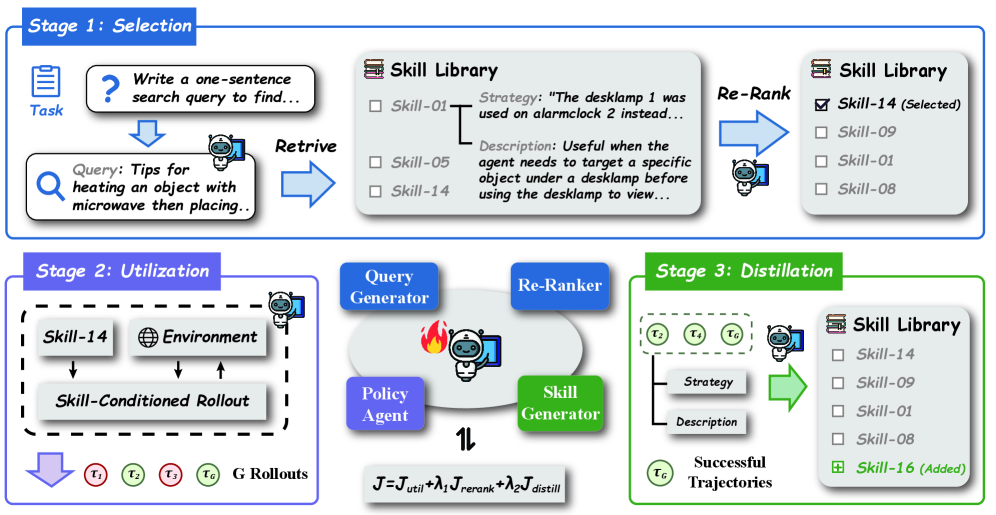
Skill1 runs agents through a three-stage lifecycle, all steered by a single reward signal — whether the task got done or not. No separate loss functions. No hand-tuned selection heuristics. Just GRPO (Group Relative Policy Optimization) applied to a Qwen2.5-7B-Instruct base model.
The three stages:
- Selection: The agent generates a query describing what it needs, retrieves candidate skills from a library, and re-ranks them.
- Utilization: The agent runs skill-conditioned rollouts — multi-turn interactions where it actually uses the selected skill.
- Distillation: After completing a task, the agent reflects on what worked and extracts a new reusable skill from the successful trajectory. That skill gets added to the library.
The encoder is a frozen all-MiniLM-L6-v2 for embedding. The library caps at 5,000 entries. Each task runs 16 rollouts, and lambda weights for the selection and distillation signals are both 0.3. Training runs 1.3x to 1.7x slower than standard GRPO.
Benchmarks
| Method | ALFWorld |
|---|---|
| Standard GRPO | 77.3% |
| SkillRL (Feb 2026) | ~85% |
| RetroAgent (Mar 2026) | 94.9% |
| Skill1 | 97.5% |
ALFWorld is a text-based household environment — pick up objects, heat them, put them in the right place. Skill1 also posted the best numbers on WebShop, a simulated e-commerce benchmark.
That 97.5% on ALFWorld matters because it's close to ceiling. There aren't many wrong moves left to fix. The jump from RetroAgent's 94.9% to 97.5% sounds small, but it means Skill1 is making fewer than half the errors.
Ablations
This is where the paper gets honest. The team stripped components one at a time:
| Variant | ALFWorld |
|---|---|
| Full Skill1 | 97.5% |
| Without Skill Library | 80.9% (-16.6) |
| Without Distillation | 92.4% (-5.1) |
| Without Selection Signals | ~88% (-9.5) |
The library is doing the heavy lifting. Remove it and you lose 16.6 points — the agent reverts to near-baseline performance. Without distillation, the library gets cluttered with stale skills and drops 5.1 points. Without proper selection signals, the agent routes to wrong skills and loses 9.5.
Prior Work
The skill-augmented agent space has been busy. SkillRL (Feb 2026) used a hierarchical SkillBank but only hit ~85% on ALFWorld. SAGE (Dec 2025) tackled AppWorld — a harder benchmark with real app UIs — and got 60.7% Scenario Goal Completion. ARISE (Mar 2026) applied a Manager-Worker hierarchy to math reasoning. Memento-Skills (Mar 2026) built an agent that designs other agents, improving 26.2% on GAIA. RetroAgent (Mar 2026) used dual intrinsic feedback signals and hit 95.6%.
Skill1's contribution is that it collapses all this complexity into one policy. No separate selection module. No separate distillation module. One model learns to do everything from the same reward signal.
Limitations
Text-based environments only — ALFWorld and WebShop don't have images, buttons, or dropdowns. The 5,000-entry library cap means there's a ceiling on how many skills an agent can accumulate. And the 1.3x to 1.7x training overhead means you're paying for the skill machinery with slower iteration.
What Surprised Me
The ablation that stuck with me isn't the big number. It's the distillation one. Only 5.1 points lost without it, which sounds like distillation barely matters. But the paper describes what actually happens: skills get stale. The library accumulates noise. The agent keeps retrieving skills that used to work but don't anymore, and it has no mechanism to clean house.
That 5.1-point drop isn't about missing new skills. It's about the old ones rotting. And that feels like the real unsolved problem here. Even with distillation, the library caps at 5,000 entries. What happens at 50,000? At 500,000? This architecture has no pruning mechanism, no way to forget.
The 97.5% on ALFWorld is impressive, but I keep thinking about what's not being measured. ALFWorld has 6 task types and a known set of object interactions. It's a closed world. Skill1 is proving it can saturate a closed world. Whether it generalizes to open-ended environments — where skills can conflict, overlap, or go stale in ways the reward signal can't detect — that's the question nobody has answered yet.