Most video generation models can do one thing. You train one to make videos from text. You train another to remove backgrounds. A third to estimate depth. A fourth to relight a scene. None of them talk to each other, and each one forgets something the last one learned.
A collaboration between HKUST, Stanford, and Tsinghua just published at SIGGRAPH 2026 shows a different approach. UniVidX starts with a single pretrained video diffusion model and teaches it 30 different tasks across two domains without catastrophic forgetting.
Architecture
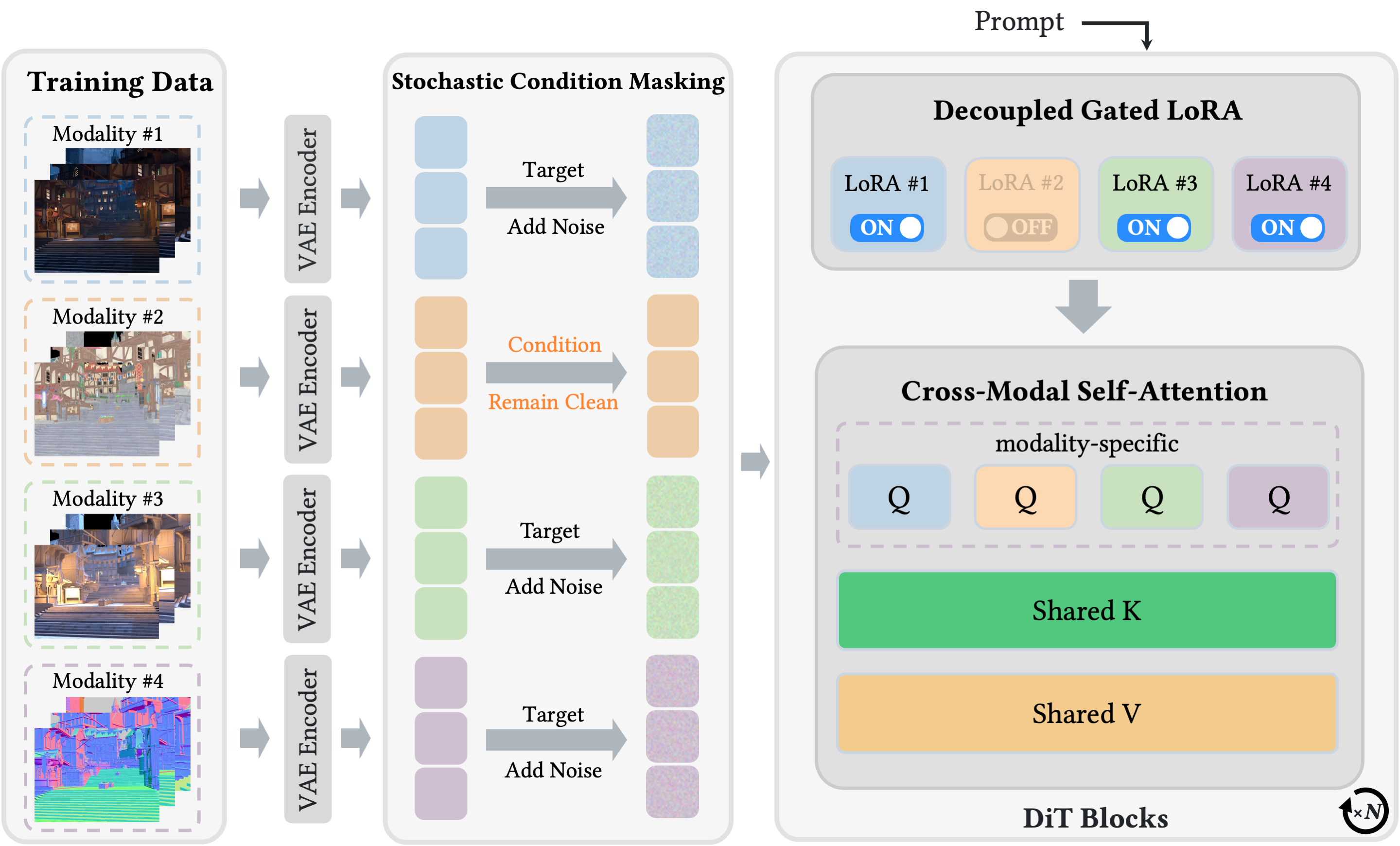
UniVidX builds on the Wan2.1-T2V-14B backbone, which gives it a strong foundation in video generation. Three architectural innovations make the unified approach work:
Stochastic Condition Masking (SCM) — During training, the model randomly decides which modalities are "inputs" and which are "outputs." Sometimes it sees an RGB video and has to predict the normal map. Sometimes it sees the normal map and has to predict the RGB video. Sometimes it gets text + one modality and has to predict the other. This single mechanism enables three generation paradigms: Text→X, X→X, and Text&X→X, all in one model.
Decoupled Gated LoRA (DGL) — Each modality gets its own LoRA adapter with a gate. When a modality is the generation target, its LoRA activates. When it's an input condition, the LoRA stays off. This keeps the backbone's original video-generation priors intact while letting each downstream task specialize. Ablations show that disabling gating drops albedo PSNR by 1.87 dB.
Cross-Modal Self-Attention (CMSA) — Keys and values are shared across all modalities while queries stay modality-specific. This creates a shared representation space where the model can learn what an edge looks like whether it appears in RGB, depth, albedo, or alpha. The attention maps the visual structure of a scene once and routes it to whichever output modality is requested.
Two model instantiations were built:
- UniVid-Intrinsic — RGB video ↔ intrinsic maps (albedo, irradiance, normal). Enables video relighting, material editing, and inverse rendering.
- UniVid-Alpha — Blended RGB ↔ RGBA layers (foreground, background, alpha matte). Enables video matting, inpainting, and background replacement.
Each instantiation handles 15 tasks, for 30 total.
Benchmarks
| Task | Metric | UniVidX | Previous SOTA |
|---|---|---|---|
| Normal Estimation | MAE (degrees) | 11.09 | 13.75 (NormalCrafter) |
| Albedo Estimation | Intensity Error | 0.44 | 0.48 (Diffusion Renderer) |
| Irradiance Estimation | Intensity Error | 0.23 | 0.26 (Diffusion Renderer) |
| Video Matting | MAD | 4.24 | 5.67 (RMG) |
| Temporal Flickering | Score (1=best) | ~1.0 | 1.5+ (image baselines) |
All benchmarks show a clean lead across the board. The normal estimation result is particularly notable — NormalCrafter at 13.75° was already strong, and UniVidX shaved off nearly 3 degrees of error.
Training efficiency: Both models achieve these results despite training on fewer than 1,000 videos each. UniVid-Intrinsic trained on InteriorVid (synthetic indoor scenes). UniVid-Alpha trained on VideoMatte240K (green-screen clips). In-the-wild generalization was robust even with this limited domain-specific data.
Compute: 4x NVIDIA H100, BF16 mixed precision, AdamW optimizer with cosine annealing. The 14B parameter backbone limits output to 21 frames at 480p — a practical constraint for now.
Community Reaction
The paper landed on HuggingFace with 70 upvotes within its first day, ranking it among the most popular papers of the day. The SIGGRAPH 2026 acceptance and ACM TOG publication signal strong peer validation. Open-source code and model weights are available on GitHub and HuggingFace.
The broader context: we are seeing a shift from task-specific video models (one for matting, one for depth, one for generation) toward unified frameworks. Meta released WorldGen for text-to-3D worlds. Black Forest Labs pushed FLUX.2. The question is no longer "can a diffusion model do X" but "how many X's can one model learn without forgetting the first one."
What Surprised Me
Two things stand out.
First, the data efficiency. Training on under 1,000 domain-specific synthetic videos and getting in-the-wild generalization is not something I expected. Typical intrinsic image decomposition needs thousands of diverse scenes with ground truth. UniVidX manages it by leaning hard on the VDM backbone's priors — the Wan2.1 model already "knows" what a room looks like, so the fine-tune just teaches it to map that knowledge into new output spaces.
Second, the decoupled LoRA gating strategy is elegant in its simplicity. Each new task gets its own small parameter set and only activates when needed. This avoids the structural collapse that naive channel-concatenation approaches hit in low-data regimes. The ablation is convincing: without gating, performance across all tasks degrades.
The limitation is real, though. 21 frames at 480p is short, and the 14B backbone demands serious hardware. This is not something you run on a single RTX 4090. But as a research direction — one model, 30 tasks, no forgetting — it points somewhere useful.
Sources
https://arxiv.org/abs/2605.00658 https://houyuanchen111.github.io/UniVidX.github.io/ https://huggingface.co/papers/2605.00658 https://arxiv.org/html/2605.00658v1 https://huggingface.co/houyuanchen/UniVidX https://github.com/houyuanchen111/UniVidX