Your $2,600 RULER Run Just Cost $8
There are two kinds of AI startups. Ones that ship models, and ones that ship benchmarks. Subquadratic launched May 5 with eye-popping numbers and precisely zero code you can touch. Thirteen employees, eleven PhDs, $29 million in seed funding at a $500 million valuation — and no public weights, no API key you can request, no paper accepted anywhere.
I want this to be real. I also remember Magic.dev.
Architecture
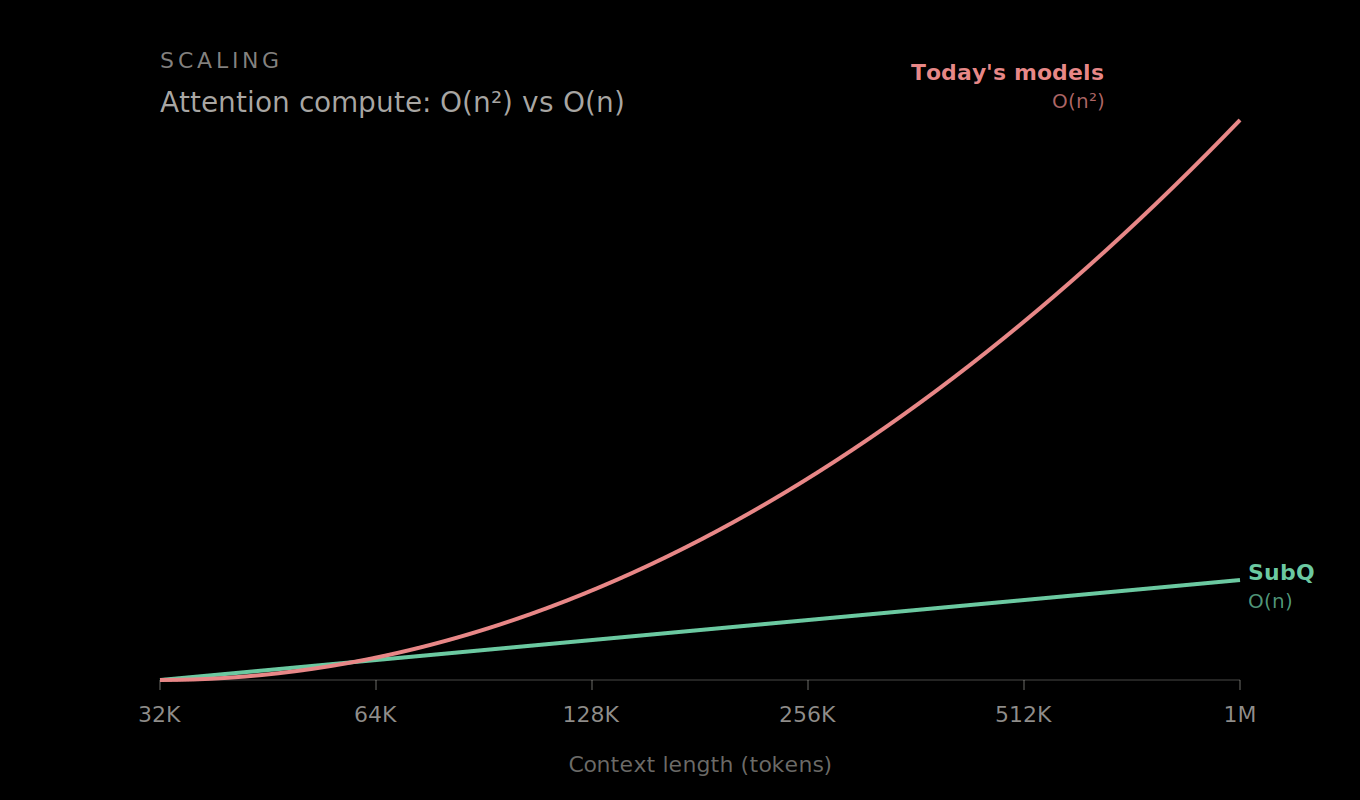
Subquadratic's pitch rests on something they call Sparse Sparse Attention — a double application of sparsity. Standard attention compares every token to every other token. O(n²). SSA routes queries through a learned gating function that selects only relevant key-value pairs, dropping the complexity to O(n). They call this "content-dependent sparse routing."
The speed claims at 1M tokens on a B200: 52.2x faster than FlashAttention, with a 62.5x reduction in total FLOPs. At 128K tokens, the gain is a more modest 7.2x — which is actually the more believable number.
The real provocation isn't the scaling. It's the target. SubQ's CEO Justin Dangel frames their strategic goal bluntly: make RAG, vector databases, and chunking strategies obsolete. A world where you just dump everything into context and let the model figure it out.
Benchmarks & Cost
Benchmark performance lands in Claude Opus territory, with one number that drew every skeptic's eye:
| Benchmark | SubQ | Claude Opus |
|---|---|---|
| RULER 128K | 95.0% | 94.8% |
| SWE-Bench Verified | 81.8% | 80.8–87.6% |
| MRCR v2 (Research) | 83.0 | 78.0 |
| MRCR v2 (Production) | 65.9 | 32.2 |
The cost differential is where the pitch gets flammable. SubQ claims a RULER 128K run costs roughly $8, versus ~$2,600 for Claude Opus. That's 325x cheaper. Extrapolated to 12M tokens, they claim a ~1,000x reduction in attention compute.
The MRCR v2 gap between research and production variants — 83 vs 65.9 — deserves scrutiny. That's a 17-point drop going from lab to deployable. Claude's gap is even wider at 45.8 points, but Claude's production number is the one you can actually run. SubQ's production number doesn't have an API behind it yet.
| Approach | Truly Subquadratic? | Limitation |
|---|---|---|
| SSA (SubQ) | Claims yes | Unverified |
| Mamba / RWKV | Yes | Underperforms on complex reasoning |
| Kimi Linear | Hybrid | Uses MLA for quality-critical layers |
| DeepSeek DSA | No | Quadratic indexer stage |
Community
HN landed somewhere between "this changes everything" and "show us the weights." Several commenters pointed out the Magic.dev parallel — a 2024 startup that made similar bold claims about long-context breakthroughs, raised significant funding, and delivered nothing. A LessWrong post titled "Debunking claims about subquadratic attention" laid out the theoretical counterargument: some tasks provably require quadratic attention under the Strong Exponential Time Hypothesis, suggesting SSA either doesn't achieve true subquadratic or doesn't maintain quality on those tasks.
"The benchmarks look incredible, but single-run numbers from a company with no public API and no paper are marketing, not science." — HN top comment
"If this is real, it's the most important AI paper since Attention Is All You Need. If it's not, it's Magic.dev all over again." — Reddit /r/MachineLearning
What's conspicuously absent: any independent reproduction. Eleven PhDs and no arXiv preprint.
Sources
- SubQ launch announcement
- SSA architecture deep-dive
- VentureBeat: researchers demand independent proof
- SiliconANGLE coverage
- ExplainX technical breakdown
- HN discussion
- LessWrong: debunking SSA claims
So What
Three numbers matter here. The rest is theater.
First: that MRCR v2 production score of 65.9. It's the only benchmark where SubQ runs the same config a customer would get, and it's a real needle-in-haystack test that correlates with long-context usefulness. It handily beats Claude's 32.2. If reproducible, that's actual value.
Second: the 17-point gap between research and production MRCR scores. Big gaps between lab and deployable configs usually mean something breaks in the compression. Watch this number. If it closes, SubQ is shipping something real. If it doesn't, they're selling the lab variant while delivering the production one.
Third: the absence of a paper. Not a preprint on arXiv. Not a technical report. Eleven PhDs and $29 million and nobody has submitted anything for peer review. The architecture section of their website uses clean diagrams and precise formulas, which means they have the math. They're choosing not to publish it. That's a business decision, not a scientific one.
The Magic.dev comparison isn't entirely fair — SubQ has more specific technical claims, named researchers, and at least some community reproduction happening through reverse-engineering from the blog post. But $500 million valuations on unpublished work with no public access are how hype cycles form.
If SubQ is real, RAG stops being infrastructure and becomes a fallback for models that can't handle long context. Vector databases, chunking strategies, retrieval pipelines — all of it goes the way of hand-crafted NLP features. That's a genuinely big deal.
If it's vapor, it's the most expensive vapor in the room right now.
The only thing that settles this is access. Ship the API. Release a small model. Put up a technical report with enough detail for someone at DeepSeek or Meta to try reproducing the routing mechanism. Until then, SubQ is a $29 million bet that subquadratic attention works at scale — placed by investors, not by anyone who's run the model themselves.