Your LLM generates one word at a time. This one doesn't.
ByteDance just published Cola DLM, a 2.3B parameter language model that ditches autoregressive token prediction entirely. Instead, it works in continuous latent space — compressing meaning first, then generating text from that compressed representation. The result? Scaling behavior that actually beats autoregressive models on reasoning benchmarks.
How It Works
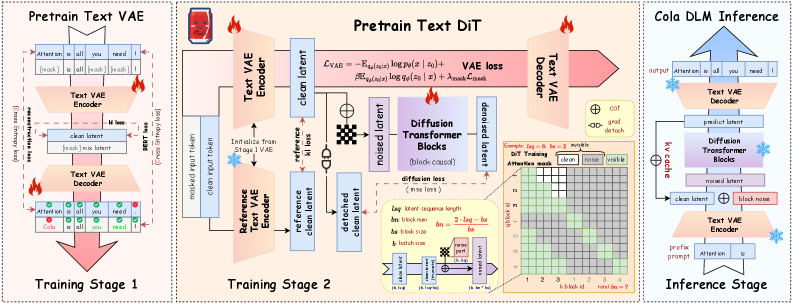
Cola DLM (Continuous Latent Diffusion Language Model) decomposes text generation into three stages:
Stage 1 — Text VAE (500M params): A variational autoencoder maps discrete tokens into a continuous latent space. The encoder is strictly causal — it sees past tokens but not future ones. Training uses reconstruction loss, BERT-style masked prediction, and KL divergence.
Stage 2 — Block-Causal DiT (1.8B params): A Diffusion Transformer models a global semantic prior in continuous latent space using Flow Matching. The key architectural choice: block-causal attention with block size 16 (the sweet spot — beats fully causal blocks and large blocks alike). Training uses a logit-normal noise schedule with loc=1.0. Only 8-10 denoising steps are needed for most gains.
Stage 3 — Conditional Decoder: Decodes the denoised latent representation back into text tokens.
The training happens in stages: VAE pretraining first, then joint VAE+DiT co-evolution. The paper found that joint continuous evolution of both components outperforms interval-based updates — mutual adaptation matters.
Benchmarks
Cola DLM was tested across 8 benchmarks against strictly matched ~2B parameter autoregressive and LLaDA baselines — same corpora, same tokenizers, same sequence lengths, same compute budgets.
| Benchmark | Cola DLM vs AR Baseline | Notes |
|---|---|---|
| MMLU | Late-stage advantage | Reasoning-heavy, shows strongest separation at ~2000 EFLOPs |
| RACE | Notable win | Reading comprehension with reasoning |
| Story Cloze | Clear edge | Commonsense narrative understanding |
| General LM | Competitive | Matches AR baselines on standard perplexity |
The scaling curves (up to ~2000 EFLOPs) show Cola DLM pulling ahead on reasoning-intensive benchmarks as compute increases. That's the key finding: continuous latent prior modeling scales better than autoregressive modeling for tasks that require reasoning.
One critical insight from the paper: perplexity is not a good proxy for generation quality in diffusion LMs. PPL is sensitive to local probability calibration, not global semantic coherence. This explains why pure likelihood-based evaluations have historically underestimated diffusion language models.
Prior Work
Cola DLM builds on a lineage of diffusion-for-language work:
- LLaDA (arXiv:2502.09992) — discrete masked diffusion for LLMs. Shen Nie is a co-author on both papers; Cola DLM is the next evolution.
- MDLM (arXiv:2406.07524) — simple masked discrete diffusion from NeurIPS 2024.
- Latent Diffusion for Language (arXiv:2212.09462, NeurIPS 2022) — early VAE+diffusion work.
- Seed Diffusion — ByteDance's prior internal diffusion work.
The key differentiator: previous continuous diffusion approaches (Plaid, etc.) used token-aligned representations with "observation-recovery" paths. Cola DLM uses compressed latents with prior-transport — diffusion doesn't recover individual tokens, it refines a compressed semantic representation.
Community Reception
The paper has 61 upvotes on HuggingFace Papers — the highest of any recently published paper. It's been covered by AI Research Roundup on YouTube and featured on Machine Brief. The community is paying attention, but the paper is very fresh (May 2026) so substantial discussion hasn't formed yet.
What Surprised Me
The "clean condition repaint" finding is quietly important. Cola DLM keeps known (prefix) regions fixed throughout the entire denoising process rather than partially repainting them. This prevents structural mismatch and error accumulation — a gotcha that would have killed the approach if they'd picked the wrong strategy.
The block size calibration is also revealing. Block size 16 handily beats both fully causal (block=1) and large blocks (64, 128). This matters because it suggests the model is learning genuine semantic chunks — roughly sentence-fragment-sized units — rather than either token-level or paragraph-level structure. The model discovered a linguistically meaningful granularity purely from the optimization objective.
The multimodal potential is where this gets interesting. Because Cola DLM works in continuous latent space, it naturally bridges discrete text and continuous modalities (images, audio). The paper shows preliminary captioning results after training on only ~5M image-text pairs. A shared MMDiT prior could organize joint semantics across modalities — the same latent trajectory could encode "a dog running" as both text and pixels.
The honest limitation: this is a 2.3B parameter feasibility study at ~2000 EFLOPs. The real test is whether this approach scales to hundreds of billions of parameters and millions of EFLOPs. The scaling curves look promising, but we've seen promising scaling curves before.
Cola DLM doesn't replace autoregressive models today. But it opens a door that's been locked since GPT-2: what if text generation doesn't need to be a left-to-right token parade?
Sources
- https://arxiv.org/abs/2605.06548
- https://arxiv.org/html/2605.06548
- https://huggingface.co/papers/2605.06548
- https://hongcanguo.github.io/Cola-DLM/
- https://arxiv.org/abs/2502.09992 (LLaDA)
- https://arxiv.org/abs/2406.07524 (MDLM)
- https://www.youtube.com/watch?v=fuarVBjjONI (AI Research Roundup)
- https://www.machinebrief.com/news/cola-dlm-shaping-the-future-of-text-generation-lbrz