What happens when you take an autonomous research loop — the kind that's usually optimizing neural network training — and point it at a domain it has no business being good at?
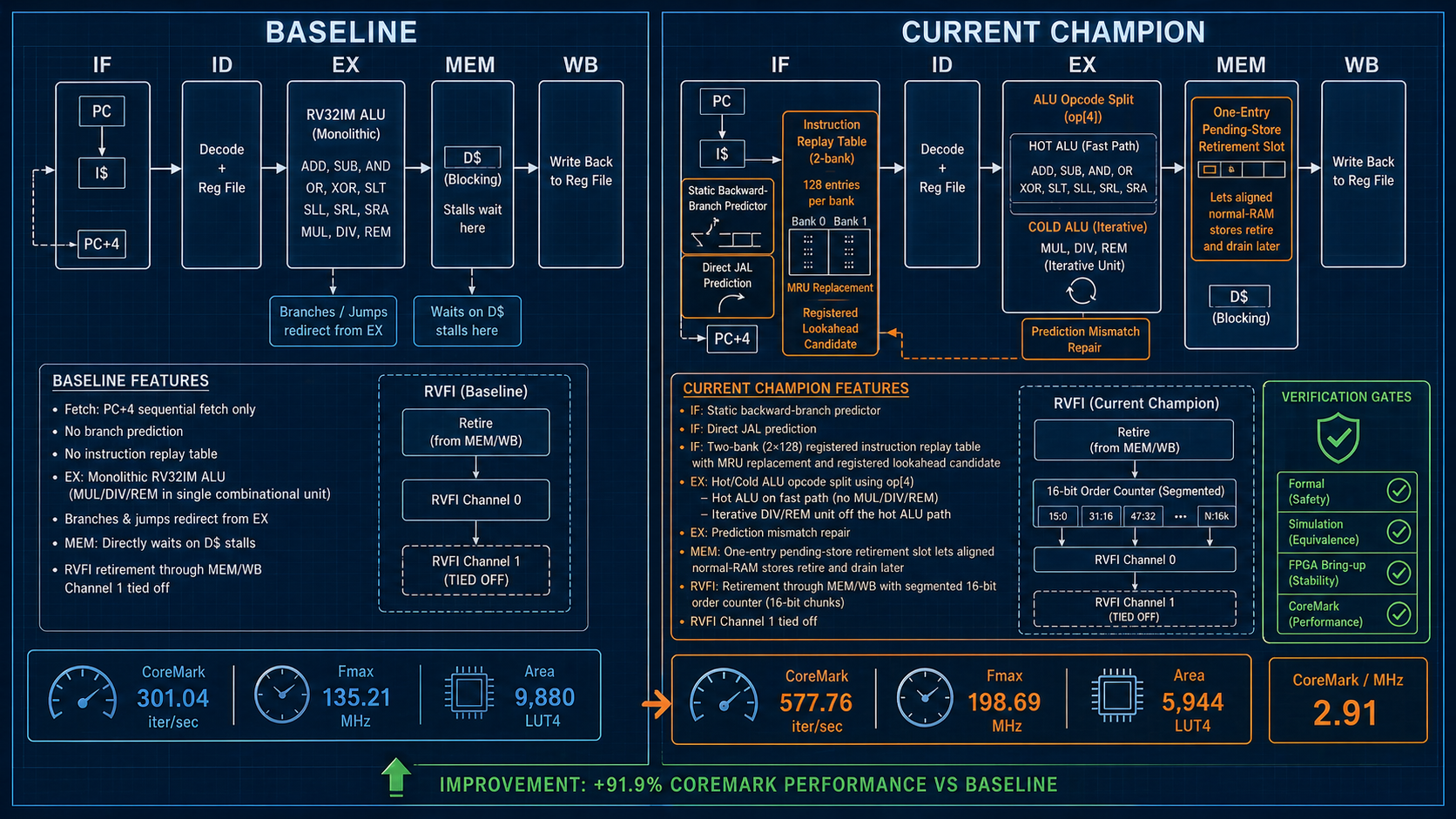
A 5-stage RISC-V CPU core, implemented in SystemVerilog, running on a cheap FPGA. The kind of thing a graduate student builds in a computer architecture class. Textbook pipeline: fetch, decode, execute, memory, writeback. No caches. No branch predictor. Nothing fancy.
Andrej Karpathy's autoresearch showed that an LLM agent, given two days and a single GPU, could find 20 training-time optimizations on its own. The pattern is deceptively simple: propose a change, implement it, measure the result, keep the wins. But the demonstration stayed on the agent's home turf — Python, gradient descent, well-known knobs.
The real question was whether this generalizes.
Turns out, it does. The interesting part is not what you'd expect.
The Setup
The auto-arch-tournament project wraps a 5-stage in-order RV32IM core with a hardcoded orchestrator that runs three parallel slots per round:
- A hypothesis agent proposes a microarchitectural change as YAML, validated against a JSON schema
- An implementation agent edits the SystemVerilog RTL in an isolated git worktree
- An eval gate runs a gauntlet: riscv-formal checks (53 symbolic BMC checks), Verilator co-simulation (RVFI byte-identical against a Python ISS), 3-seed nextpnr place-and-route on a real Gowin GW2A-LV18 FPGA (Tang Nano 20K), and CoreMark CRC validation
If the change improves fitness — measured as median Fmax × CoreMark iter/cycle — it merges. If it regresses, breaks formal, or fails placement, the worktree is destroyed.
A diversity rotation forces each slot to pick a different category per round — micro-optimization, structural, predictor, memory, extension — so the agent doesn't fixate on one idea type.
The Numbers
73 hypotheses. 9 hours, 51 minutes. 10 accepted.
The baseline: 301 iter/s, 2.23 CoreMark/MHz, 135 MHz Fmax, 9,880 LUT4.
Final state: 578 iter/s, 2.91 CoreMark/MHz, 199 MHz Fmax, 5,944 LUT4.
That's +92% over the locked baseline and +56% over VexRiscv — a human-tuned reference implementation that took years to reach its current state. With 40% fewer LUTs.
The win compounds. About 13% of it is architectural efficiency (2.91 vs 2.57 CoreMark/MHz). The rest is Fmax — a smaller, simpler design that the synthesizer clocks faster.
The breakthrough came at iteration 3: pulling DIV/REM out of the single-cycle ALU path. The agent did not know that would also halve the LUT count. It found out by doing it and watching the synthesizer.
63 Out of 73 Hypotheses Were Wrong
This is the part that matters.
Fifty regressions. Nine broken — failed formal verification or co-simulation. Four failed placement. One hypothesis at round 24, proposed after the peak fitness was already locked, collapsed performance by 73%. A single mistake that would have undone every previous win, caught by the regression-against-baseline check before it shipped.
One idea came in twice. "Move DIV/REM off the single-cycle ALU path" first appeared at round 1 and broke co-simulation before it ever reached the FPGA. The agent rephrased it as "Cold Multi-Cycle DIV/REM Unit" two hours later — same insight, fixed implementation — and it became the breakthrough win. Without the co-simulation gate, the broken first attempt would have shipped.
Two separate hypotheses tried to add files outside the allowed rtl/ and test/ directories. The path sandbox rejected them before any evaluation ran. Because if you let the agent edit the harness, eventually it will edit the harness.
The Verifier Is the Moat
There is a lot of noise right now about agent loops. Build a planner, build a coder, give them tools, run them in parallel. The loop is mostly a solved problem. Pick a model, pick a scaffolding library, pick how many parallel slots you can afford. Whatever advantage you think you have on the loop, you have it for six months.
The thing nobody is paid to build is the verifier.
Of 73 hypotheses, 63 were wrong. The agent was a producer of mostly-broken ideas. The verifier was the only thing standing between the run and a confidently-wrong number. It did the unglamorous work: formal checks beyond just instruction arithmetic (ill, unique, liveness, cover), a path sandbox that prevents editing the evaluation harness, 3-seed place-and-route so one lucky seed doesn't fool you, CRC re-validation because CoreMark prints "Correct operation validated." even when it isn't, bracketed timing markers so warm-up doesn't corrupt your measurements.
The next wave of companies is not going to be people writing code. It's going to be people writing verifiers, with a loop running against them.
If you can write the rules down, an agent will satisfy them faster than your team will. If you can't — and most teams can't, because the rules live in three engineers' heads and a stale wiki page — the agent will satisfy a different set of rules, the ones it inferred from what it could observe. You will not notice until production.
What Comes Next
The project currently discards losers each round. The next iteration moves to a population-based search: keep the top-K every round, mutate from any of them, let dead-end branches stay dead. That should scale the search space without scaling the model bill linearly.
The next experiment swaps CoreMark for Embench. Some of those predictors clearly overfit to CoreMark's branch profile. The question is which winners survive a workload change and which were just trivia.
The deeper question — for anyone shipping a product — is which parts of your business already have a verifier sharp enough to point a loop at.
The frontier is not the model. It's not the prompt. It's not the parallel slot count.
The frontier is the verifier.