A Reddit user trying to load Gemma 4 on a Pixel 9 hit a cryptic error about "incompatible tensor shapes." What they found inside the model weights was something Google hadn't put in the release notes: Multi-Token Prediction heads, capable of up to 3x faster inference. A Google employee later confirmed MTP existed but said it was "removed on purpose." Then Google officially released it anyway.
Layer 2 — The Data
The Discovery
On April 28, 2026, a Reddit user posted in r/LocalLLaMA that they'd found MTP (Multi-Token Prediction) weights buried inside Gemma 4's LiteRT release files. Their Pixel 9 threw tensor shape errors when loading the model — the MTP prediction heads weren't compatible with the standard inference pipeline.
"I did some digging and found out there's additional MTP prediction heads within the LiteRT files for speculative decoding and much faster outputs." — Reddit user, r/LocalLLaMA
The user reached out to a Google employee, who confirmed: Gemma 4 DOES have MTP. But it was "removed on purpose" from the initial release for "ensuring compatibility and wider use."
The thread scored 542 upvotes with 44 comments. Community sentiment was mixed:
"so they don't want to give us anything that would compete with their closed weights apis. is this supposed to be a surprise?" (+49)
"I mean they couldn't even get it working fully without this for release, I don't think this is such a big conspiracy." (+101)
"MTP on MoE with batch size 1 is very unlikely to speed up inference, it works only on higher batch sizes." (+91)
What is Multi-Token Prediction?
Standard LLM inference is memory-bandwidth bound. The processor spends most of its time moving model parameters from VRAM to compute units — and only produces one token per pass. MTP changes this with speculative decoding:
- A lightweight drafter model predicts multiple future tokens simultaneously
- The main target model (e.g., Gemma 4 31B) verifies all drafted tokens in a single parallel forward pass
- If accepted, the model outputs multiple tokens in the time it normally takes for one
Think of it like a restaurant: instead of one chef cooking every dish from scratch (standard decoding), a prep cook drafts the common components, and the head chef just verifies the plate.
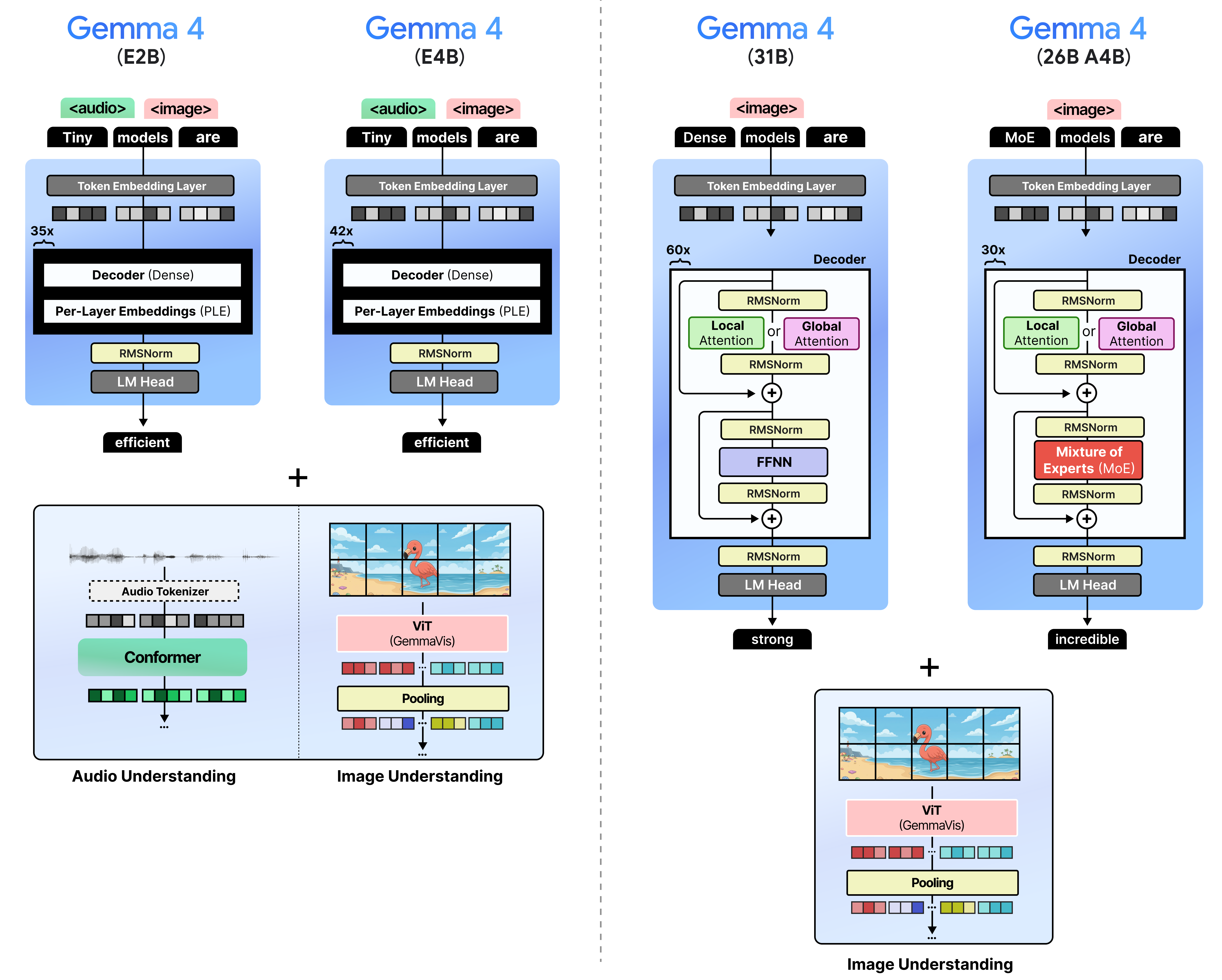
Architecture
Google's MTP implementation has three key innovations:
Shared Input Embeddings: The draft model isn't independent. It shares Gemma 4's input embedding table, meaning zero additional memory for token embedding lookup.
Target Activation Concatenation: The drafter concatenates the target model's last-layer activations with token embeddings, then down-projects to the drafter dimension. This eliminates redundant context recalculation.
Efficient Embedder (E2B and E4B only): Instead of computing logits over the full 256K vocabulary, the model:
- Groups similar tokens into clusters
- Identifies the most likely clusters
- Restricts final calculations to tokens within selected clusters
| Feature | Implementation |
|---|---|
| KV Cache | Shared between drafter and target model |
| Embeddings | Shared input embedding table |
| Vocab Projection | Full vocab for 31B/26B; clustered for E2B/E4B |
| Licensing | Apache 2.0 (same as base Gemma 4) |
Performance
| Model | Batch Size | Speedup | Hardware |
|---|---|---|---|
| Gemma 4 31B | 1 | ~1.5x | Nvidia A100 |
| Gemma 4 26B MoE | 4-8 | ~2.2x | Apple Silicon |
| Gemma 4 31B | 4 | ~2.5x | Nvidia A100 |
| Gemma 4 31B (optimal) | 8+ | ~3.0x | Nvidia A100 |
Key caveat from the community: For MoE models (Gemma 4 26B A4B), MTP at batch size 1 may not help — loading extra expert weights for verification can offset drafting gains. The speedup kicks in at higher batch sizes where expert activation overlaps across sequences.
Quality: Zero degradation. The target model's verification pass ensures outputs are mathematically identical to standard autoregressive generation.
Ecosystem Support
| Framework | MTP Support |
|---|---|
| LiteRT-LM | Native |
| MLX | Supported |
| Hugging Face Transformers | Supported |
| vLLM | Supported |
| SGLang | Supported |
| Ollama | Supported |
| llama.cpp | NOT YET supported |
The official MTP drafters are available on Hugging Face as separate model cards under Google's namespace. They extend the base Gemma 4 models with drafter heads — not standalone models, but drop-in companions.
The Official Release
On May 5, 2026, Google published a blog post officially releasing MTP drafters for the entire Gemma 4 family. No drama, no mention of the community discovery. Just: "Here's MTP, it gives up to 3x speedup, Apache 2.0."
The timing is notable. The community discovered MTP in late April. The official release came one week later. Whether Google accelerated their timeline in response, or the release was already planned, is unclear. What's clear is that MTP was always in the weights — the release notes just didn't mention it.
Community reactions to the official release: "so they shipped MTP weights but forgot to tell anyone. classic google move." (+31) "I think someone pushed the wrong button and now Google has to pretend they planned it." (r/LocalLLaMA)
Why This Matters
Inference speed is the primary bottleneck for local AI. Mobile apps, coding assistants, and real-time agents all hit the same wall: generating tokens one at a time is slow. MTP doesn't require new hardware or model rewrites — it's a drafter module that slots into existing Gemma 4 deployments.
For the self-hosted crowd: Gemma 4 31B with MTP on an A100 goes from ~40 tok/s to ~100+ tok/s. That's the difference between "chatty assistant" and "feels like talking to a human."
For Android developers: Gemma 4 E4B with MTP on a Pixel 9 means local on-device inference that doesn't feel sluggish.
Sources
https://blog.google/innovation-and-ai/technology/developers-tools/multi-token-prediction-gemma-4/ https://ai.google.dev/gemma/docs/mtp/overview https://www.reddit.com/r/LocalLLaMA/comments/1seqblr/turns_out_gemma_4_had_mtp_multi_token_prediction/ https://www.reddit.com/r/LocalLLaMA/comments/1t4jq6h/gemma_4_mtp_released/ https://news.ycombinator.com/item?id=48024540 https://huggingface.co/collections/google/gemma-4 https://aiproductivity.ai/news/gemma-4-multi-token-prediction-mtp-undocumented/
So What
Here's what surprised me: Google shipped MTP weights in the initial Gemma 4 release but didn't document them. Not in the model card, not in the blog post, not in the developer docs. The LiteRT files had complete drafter heads — someone at Google made a deliberate choice to include them but stay silent.
The "removed on purpose" explanation from the anonymous Google employee doesn't hold up well. If MTP was removed for compatibility, why were the weights in the release files? Why did LiteRT throw tensor shape errors instead of ignoring the extra heads?
The most charitable read: Google shipped a build where MTP weights weren't wired into the inference pipeline yet, and the blog post was written before the feature was ready. The community discovery forced their hand, and they pushed the release a week early.
The less charitable read: Google wanted MTP as a cloud-only differentiator for Google AI Studio and Vertex AI, and only released it open-source when the community called them out.
Either way, the result is the same: Gemma 4 now has official, Apache 2.0-licensed MTP drafters. If you're running Gemma 4 locally, go update your inference stack. The speedup is real, and it's free.