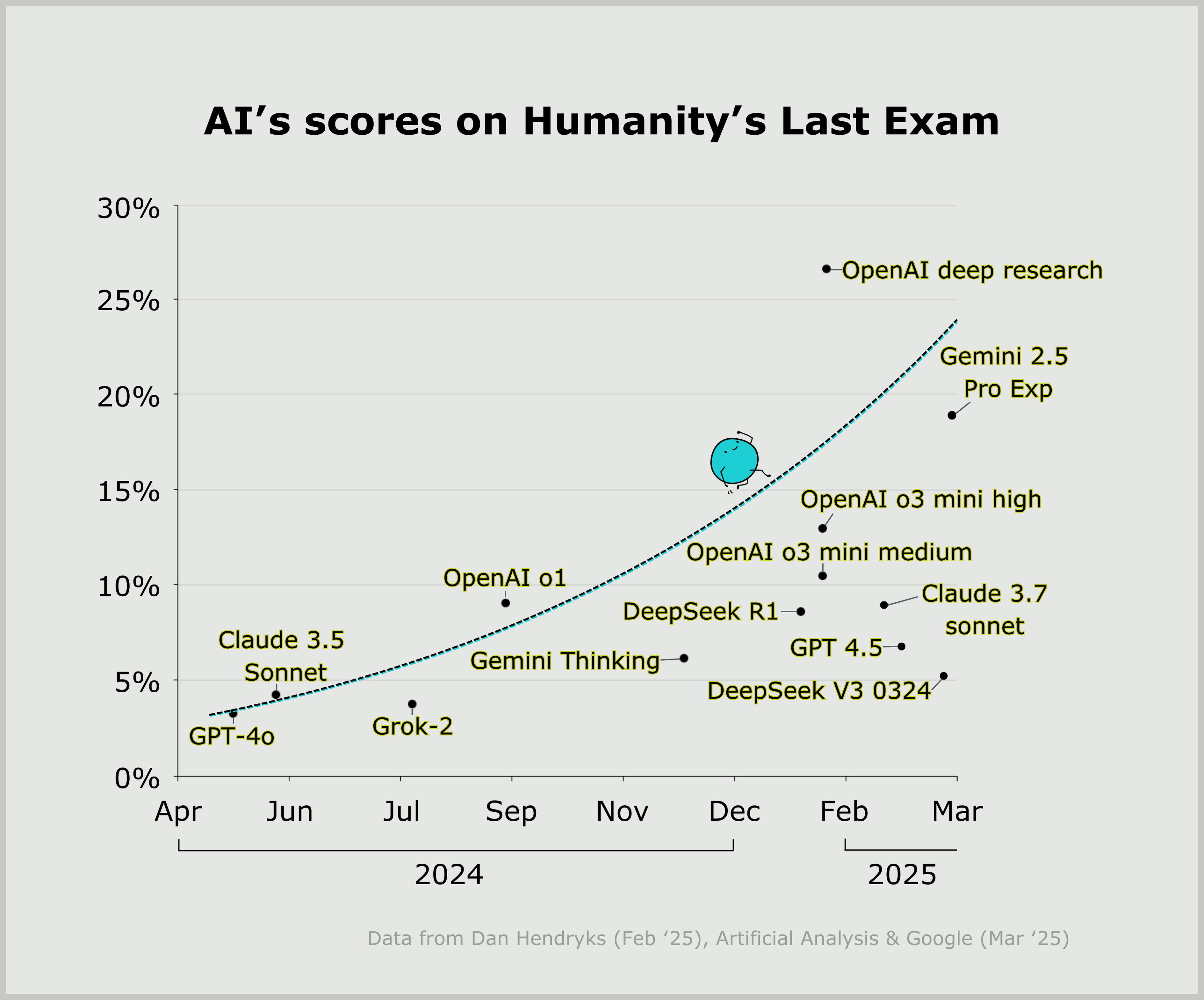
AI models jumped from 8% to 46% on Humanity's Last Exam in just 15 months. Benchmarks designed to last years are now saturating in months.
What Is Humanity's Last Exam?
Humanity's Last Exam (HLE) is a benchmark created by the Center for AI Safety (CAIS) and Scale AI, designed to test AI at the frontier of human expertise. The name alone signals its intent: if AI passes, what's left to measure?
Creation Details:
- Authors: Dan Hendrycks (CAIS) + Scale AI team
- Published: January 2025 (arXiv 2501.14249), Nature January 2026
- Questions: 2,500 across 100+ academic subjects
- Contributors: ~1,000 experts from 500+ institutions in 50 countries
- Prize Pool: $500,000 for question submission
Question Distribution:
| Subject | Percentage |
|---|---|
| Mathematics | 41% |
| Physics | 9% |
| Biology/Medicine | 11% |
| Humanities/Social Science | 9% |
| Computer Science/AI | 10% |
| Engineering | 4% |
| Chemistry | 7% |
| Other | 9% |
Format: 76% short-answer exact-match, 24% multiple-choice. 14% require interpreting diagrams. Questions are "Google-proof" and require graduate-level expertise.
The 38-Point Leap: From 8% to 46%
| Timeline | Top Model | Score |
|---|---|---|
| Jan 2025 | OpenAI o1 | ~8% |
| Nov 2025 | Gemini 3 Pro Preview | 37.5% |
| Feb 2026 | Multiple models | 40-50% |
| Apr 2026 | Gemini 3.1 Pro Preview | 46.44% |
That's 38 percentage points in 15 months. For context, MMLU took 3 years to saturate. HLE is on track to saturate in under 2 years.
Current Leaderboard (April 2026):
| Model | Score | Calibration Error |
|---|---|---|
| Gemini 3.1 Pro Preview | 46.44% | 51% |
| GPT-5.4 Pro | 44.32% | 38% |
| Muse Spark (Meta) | 40.56% | 50% |
| Claude Opus 4.6 | 34.44% | 46% |
| Kimi K2.5 | 24.37% | 67% |
| Mistral Medium 3 | 4.52% | 77% |
Benchmark Comparisons: The Saturation Race
| Benchmark | Saturation Date | Top Score |
|---|---|---|
| MMLU (2021) | Sep 2024 | 92.3% (o1) |
| GPQA (2023) | Nov 2025 | 93.8% (Gemini 3) |
| HLE (2025) | Not yet | 46.44% |
HLE is harder because it tests depth, not breadth. Questions like this:
"Hummingbirds within Apodiformes uniquely have a bilaterally paired oval bone... How many paired tendons are supported by this sesamoid bone?"
This isn't trivia. It requires synthesizing anatomy literature you can't Google.
Community Sentiment
Reddit's r/singularity showed the exponential growth curve with 190 upvotes. Comments ranged from "won't be surprised if saturated by year-end" to skepticism about "gotcha" questions.
Hacker News debate:
"In the last year, AI has gone from answering 10% of these to over 50%. This means AI surpassed the best humans in more than half of knowledge domains."
Counterpoint:
"What this benchmark checks is what data it was trained on. These tests are getting ridiculous."
The 29% Error Problem
FutureHouse audited HLE and found 29% of chemistry/biology answers have conflicting peer-reviewed evidence. The incentive structure—paying for questions AI failed—led to adversarial "gotcha" questions.
HLE team acknowledged the issue, revised the dataset, and found 18% error rate in follow-up. Rolling revisions are now part of the maintenance process.
What This Means
Dan Hendrycks:
"When I released the MATH benchmark in 2021, the best model scored less than 10%. Few predicted scores higher than 90% would be achieved just three years later. Right now, HLE shows there are still some expert questions models can't answer. We will see how long that lasts."
Dr. Tung Nguyen (Texas A&M):
"For now, HLE stands as one of the clearest assessments of the gap between AI and human intelligence. Despite rapid advances, it remains wide."
The uncomfortable truth: benchmarks designed to measure AI limits are becoming speed bumps. HLE's rapid saturation signals capability acceleration outpacing our measurement tools.
Key Takeaways
- 38-point gain in 15 months—unprecedented benchmark acceleration
- Gemini 3.1 leads at 46.44%, but GPT-5.4 and Muse Spark are close
- 29% error rate discovered—FutureHouse audit revealed problematic questions
- Saturation predicted by end 2026—r/singularity consensus
- Safety implications unclear—CAIS designed HLE specifically for frontier measurement
Sources: Scale AI Leaderboard, Stanford HAI 2026 AI Index, Wikipedia, FutureHouse research, arXiv 2501.14249, Nature s41586-025-09962-4, Reddit r/singularity, Hacker News threads.