Kimi-Dev-72B: Moonshot AI's Open-Source Coding SOTA
What It Is
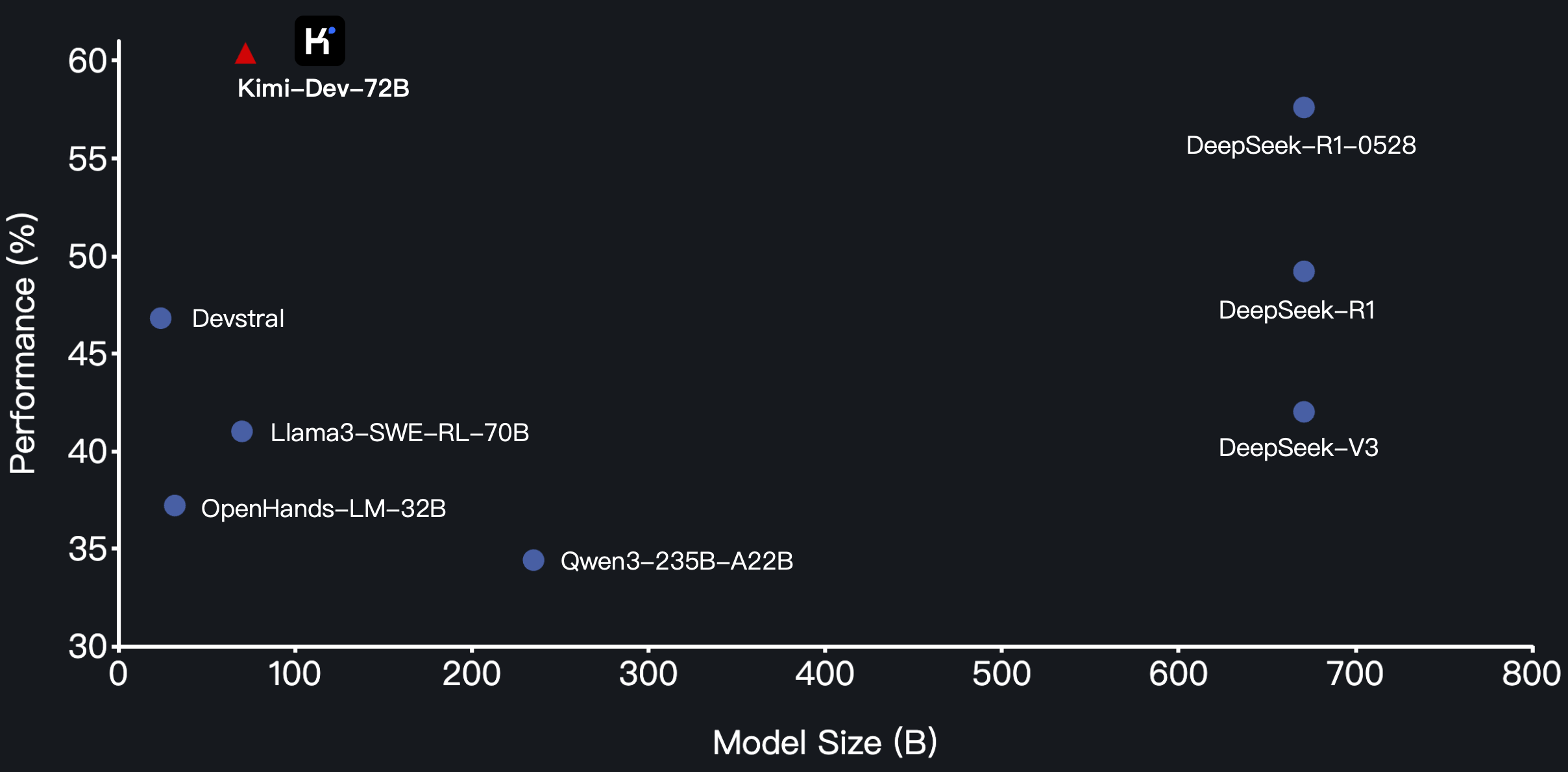
Kimi-Dev-72B is Moonshot AI's answer to the coding agent problem. It hit 60.4% on SWE-bench Verified — the highest score ever recorded by an open-source model on real-world software engineering tasks.
The model doesn't just autocomplete code. It autonomously patches real repositories in Docker containers and only gets rewarded when the entire test suite passes.
Built on Qwen2.5-72B (72.7B dense parameters, not MoE), the model uses a novel training approach called "Agentless Training as Skill Prior" that bridges workflow-based and agentic frameworks.
Technical Specs
| Parameter | Value |
|---|---|
| Total Parameters | 72.7B (dense) |
| Base Model | Qwen2.5-72B |
| Context Window | 128K tokens |
| License | MIT (fully open) |
| Precision | BF16 (80 sharded safetensors) |
| Downloads | 60,926+ on HuggingFace |
Benchmarks
| Model | SWE-bench Verified |
|---|---|
| Kimi-Dev-72B | 60.4% (SOTA open-source) |
| Gemini 3 Flash (high reasoning) | 75.8% |
| GPT-5-2 Codex | 72.8% |
| DeepSeek V3.2 | 70.0% |
| Claude 3.5 Sonnet | 48.6% pass@1 (agentic) |
The gap between Kimi-Dev and frontier closed models is narrowing. Gemini 3 Flash beats it by 15%, but Kimi-Dev runs locally for free.
How It Works
Two-Stage Framework
BugFixer: Identifies files needing modification, performs localization at file level.
TestWriter: Writes tests to verify correctness, self-reflection capabilities.
The duo approach means the model learns both how to fix bugs AND how to validate its own fixes — a crucial capability for production reliability.
Training Method
- Mid-training: ~150B tokens on GitHub issues and PR commits
- RLVR (Reinforcement Learning with Verifiable Rewards): Test suite pass/fail as sole reward signal
- Outcome-based rewards only: No format rewards, no process rewards — just execution results
The RL stage uses curriculum learning, gradually increasing task difficulty.
Cursor Connection
Cursor's Composer 2 is built on Kimi K2.5 (a related Moonshot AI model).
A developer intercepted the model ID kimi-k2p5-rl-0317-s515-fast in API traffic. Cursor confirmed their model started from Kimi K2.5 open weights.
| Kimi K2.5 Spec | Value |
|---|---|
| Total Parameters | ~1 Trillion |
| Active (MoE) | ~32B |
| Experts | 384 |
| Context Window | 256K |
Community Verdict
Reddit r/LocalLLaMA user (Thrumpwart):
"I loaded up Kimi Dev (MLX 8 Bit) and gave it a large Prolog codebase. After the first run it pinpointed the problem and provided a solution. It's very 'thinky' and unsure of itself in reasoning tokens, but it comes through in the end."
Skeptic view:
"It's just overfitting to specific benchmarks. Usually weaker in daily use."
Hardware Requirements
Full BF16 (144GB+ VRAM):
vllm serve Kimi-Dev-72B --tensor-parallel-size 8 --gpu-memory-utilization 0.95
8x A100/H100 80GB recommended.
Quantized: MLX 8-bit runs on high-end Mac (Apple Silicon).
Limitations
- 72B dense — no MoE efficiency
- Slow with long context (115K tested)
- Benchmark skepticism from some users
- No official temperature/settings guide