Hacker News called it back in March: diffusion language models might make most of the AI engineering stack obsolete. Inclusion AI just dropped the proof.
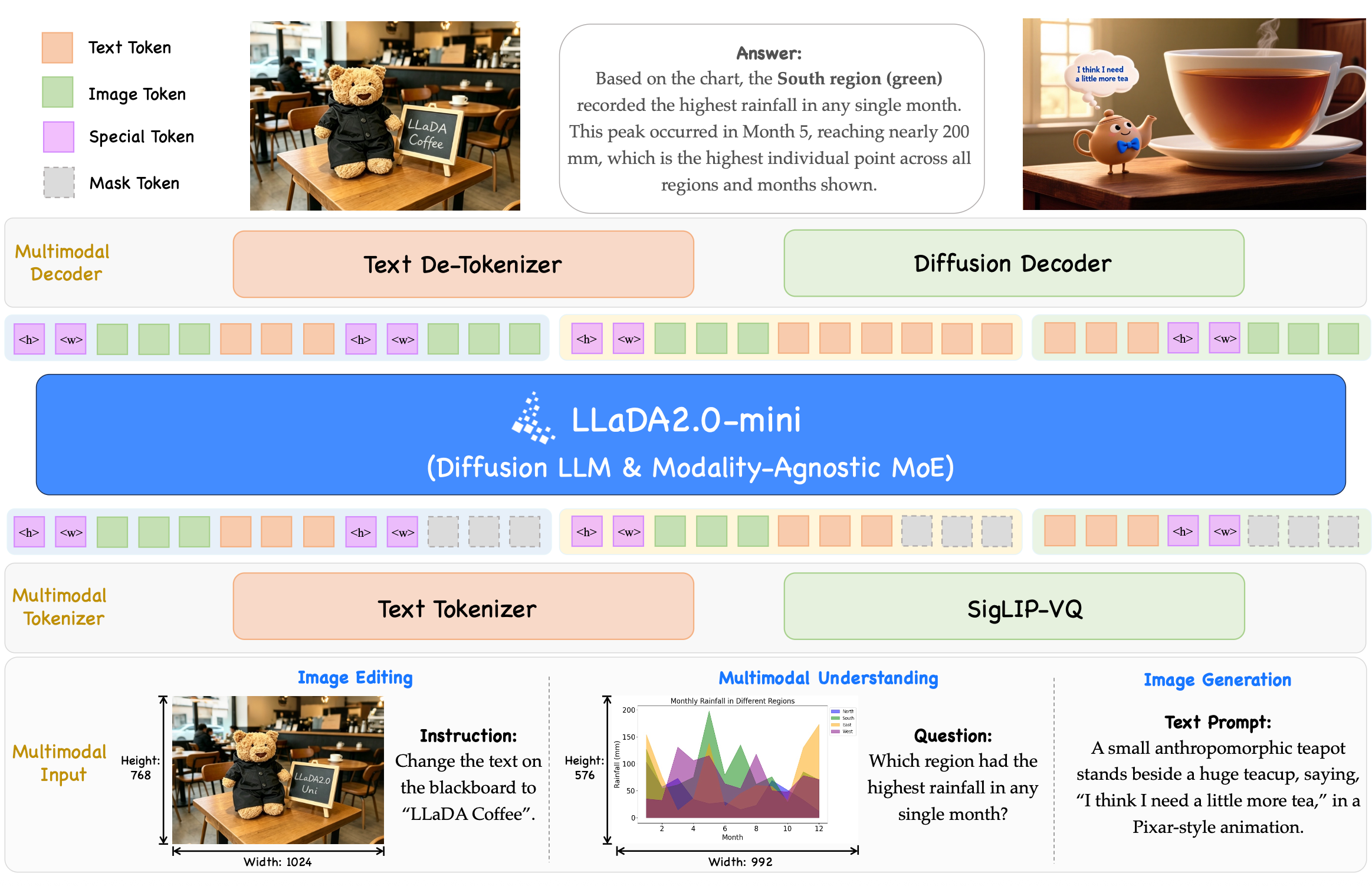
LLaDA2.0-Uni is a 16B parameter Mixture-of-Experts diffusion LLM that does both vision understanding AND image generation in a single model. That's not a hybrid. No autoregressive backbone stapled to a diffusion decoder. Pure masked diffusion for text and vision, unified from the ground up.
The architecture is clean: SigLIP-VQ tokenizer converts images to discrete semantic tokens (16,384 vocabulary, not pixel-level reconstruction), a 16B MoE backbone processes everything with ~1B active parameters per token, and an 8-step diffusion decoder reconstructs outputs. Three stages of training across 390B tokens.
The benchmarks matter because this is the first pure diffusion unified model to close the gap with specialists.
Understanding: MMStar 64.1, beating Lumina-DiMOO by +6.1. MMMU 50.1 (+5.2). SimpleVQA 44.0 vs Lumina's 12.1—that's a 31.9 point gap.
Generation: GenEval 0.89 overall, highest Position score 0.90 among all models tested. DPG 87.76, competitive with FLUX.1-dev's 83.84.
The real differentiator: MICo-Bench multi-reference editing at 47.1, SOTA ahead of Qwen-Image-Edit (35.9) and OmniGen2 (33.8). This is instruction-based image editing with multiple reference images—something AR-based models struggle with.
Thinking mode adds +10% on WISE benchmark (0.68 to 0.78). The model can reason before generating, similar to how Chain-of-Thought improves LLM outputs.
SPRINT acceleration: 1.6x throughput with only -0.6 score drop. DocVQA jumps from 8.0 to 27.6 TPS (3.5x).
Hardware: 47GB GPU memory for generation/editing, 35GB for understanding-only tasks. Not consumer-grade yet, but the efficiency curve is promising.
The paradigm shift is real. Diffusion LMs can parallelize token generation, speculatively decode, and avoid the token-by-token bottleneck of autoregressive models. Mercury 2 hit ~1000 tok/s earlier this year. LLaDA2.0-Uni isn't at that scale yet, but the architecture proves unified diffusion works.
Paper: arXiv:2604.20796 Model: huggingface.co/inclusionAI/LLaDA2.0-Uni