What It Is
A new paper from arXiv introduces LPSR (Latent Phase-Shift Rollback), a training-free inference method that corrects reasoning errors mid-generation by monitoring residual streams, detecting "phase shifts" via dual-gate mechanisms, rolling back KV-cache, and injecting steering vectors.
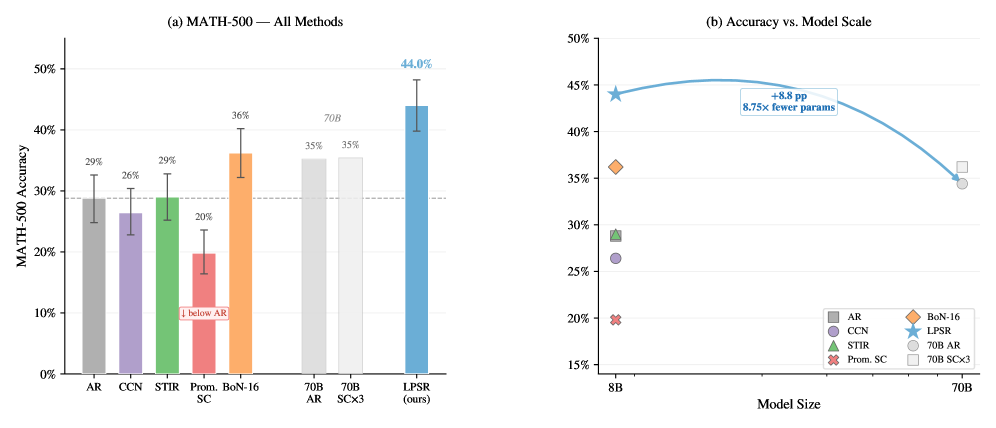
The results are staggering: an 8B model with LPSR achieves 44.0% on MATH-500 versus 28.8% standard autoregressive decoding, a +15.2 percentage point improvement. More impressively, it surpasses a 70B model (35.2%) with 8.75x fewer parameters.
How It Works
LPSR operates in three stages:
Detection: Monitors the residual stream at a critical layer (l_crit=16 for Llama 3.1 8B) using a dual-gate mechanism combining cosine similarity threshold (τ_φ ∈ [0.1, 0.3]) and entropy threshold (τ_H ∈ [2.0, 3.0])
Rollback: When a "phase shift" is detected, the KV-cache is rolled back to the pre-error state
Correction: Pre-computed steering vectors (K=142 vectors from a 50-problem calibration set) are injected to redirect generation
Key innovation: No fine-tuning, gradient computation, or additional forward passes required. Pure inference-time technique.
Benchmarks
| Method | MATH-500 Score | Notes |
|---|---|---|
| Standard AR | 28.8% | Baseline |
| Prompted Self-Correction | 19.8% | Actually degrades performance |
| Best-of-16 | 36.2% | 5.4x higher token cost |
| LPSR | 44.0% | Training-free |
| 70B Model | 35.2% | 8.75x more parameters |
Statistical significance: χ²=66.96, p<10⁻¹⁵
The Discovery: Detection-Correction Dissociation
The paper uncovers a novel phenomenon: optimal monitoring depth differs for detection versus correction.
- Error detection AUC peaks at layer 14 (0.718)
- Task accuracy peaks at layer 16 (44.0% vs 29.2%)
This "detection-correction dissociation" explains why naive approaches fail, and provides a roadmap for future inference-time methods.
Why Prompted Self-Correction Fails
The paper provides empirical evidence that asking models to "self-correct" via prompting actually degrades performance from 28.8% to 19.8%. The model's confidence remains high even when wrong, and the correction prompt introduces new errors.
LPSR avoids this by operating at the representation level, not the token level.
Cost Analysis
Compared to Best-of-16:
- +7.8 pp higher accuracy
- 5.4x lower token cost
LPSR requires a one-time calibration set (50 problems) to compute steering vectors, but adds minimal overhead during inference.
Implications
The uncomfortable truth: most production LLM deployments have zero detection for reasoning errors that accumulate mid-generation.
This work opens a new research direction: representation-level error correction as a complement to model scaling. Instead of training bigger models, we can make existing models smarter at inference time.
Limitations
- Requires calibration set (50 problems) specific to task domain
- Steering vectors are model-specific
- Currently tested on math reasoning; generalization to other domains needs study
Technical Details
- Base Model: Llama 3.1 8B
- Critical Layer: l_crit = 16 (mid-layer monitoring)
- Steering Vector Basis: K = 142 pre-computed vectors
- Calibration: 50-problem set from MATH training split
- Detection Thresholds: Cosine τ_φ ∈ [0.1, 0.3], Entropy τ_H ∈ [2.0, 3.0]
Paper
arXiv: https://arxiv.org/abs/2604.18567
Title: "Latent Phase-Shift Rollback: Training-Free Error Correction for Language Models"
Published: April 20, 2026