You've been running dense models locally because MoE felt like a compromise. Alibaba just changed the math.
Qwen3.6-35B-A3B dropped two days ago. 35 billion total parameters, but only 3 billion active per token. That's not a typo. The model routes through 8 of 256 experts per inference, delivering Qwen3.5-27B-level performance at roughly 9x the efficiency.
Let's get technical.
The Architecture
The model uses a Mixture-of-Experts design with 256 specialized experts. Each forward pass activates 8 routed experts plus 1 shared expert. This isn't the sparse MoE you're used to. The routing mechanism here is optimized for multimodal workloads. Text, images, and code flow through different expert combinations.
Native context window is 262K tokens. Extensible to 1M with YaRN or similar techniques. The Apache 2.0 license means actual commercial freedom, not the research-only handcuffs we've seen from other recent releases.
The Benchmarks That Actually Matter
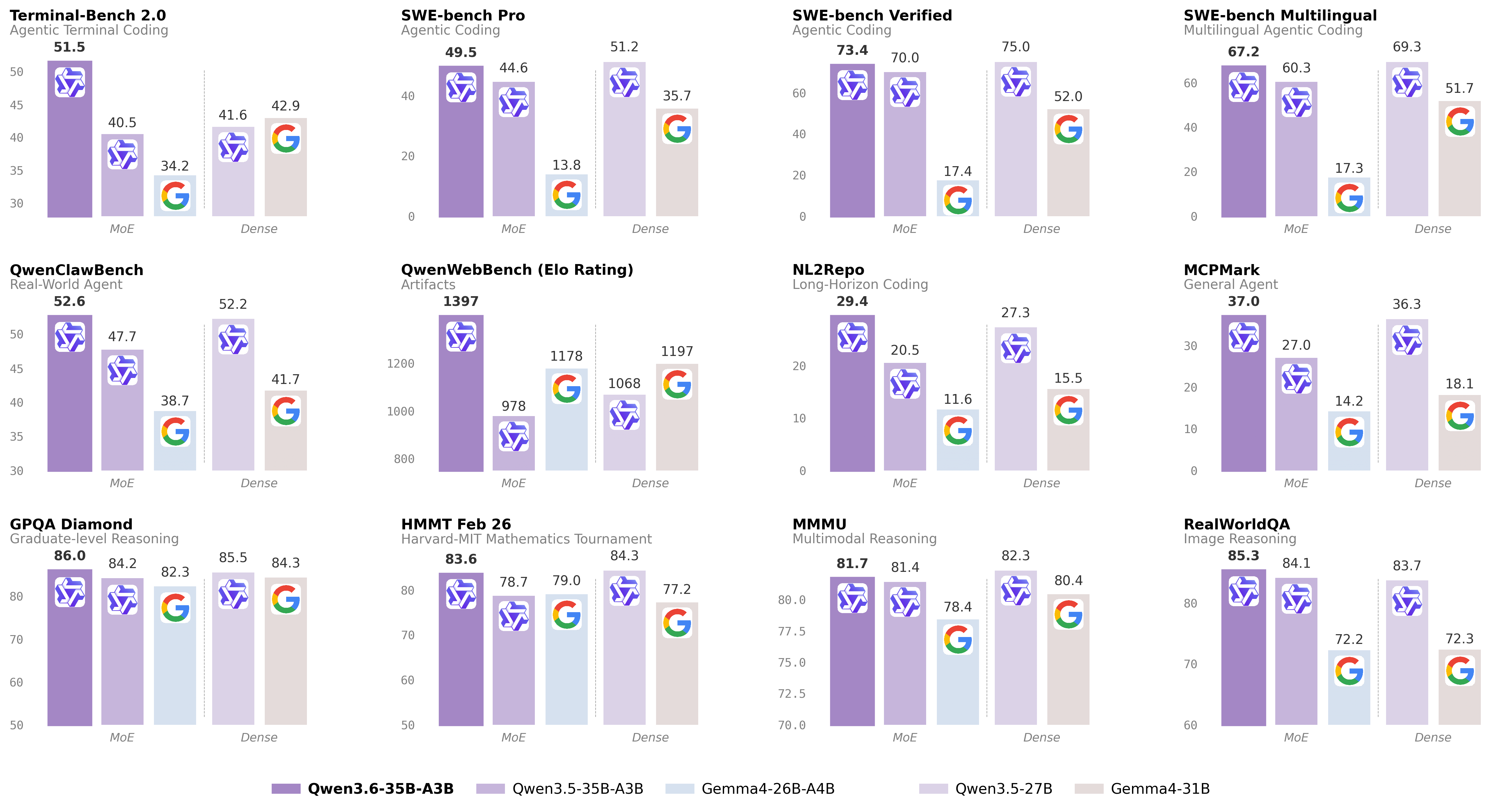
SWE-bench Verified: 73.4%. Compare that to Gemma4-31B at 52%. This isn't incremental. It's a 40% relative improvement on real-world code fixes.
Terminal-Bench 2.0: 51.5%. The previous state from Qwen3.5-27B was 41.6%. Terminal-Bench is the benchmark that actually tests agentic coding. Your model gets dropped into a shell and has to figure things out. Qwen3.6-A3B passed half the tasks.
Multimodal benchmarks are solid too. MMMU at 69.7%, VideoMME at 66.3%. It sees and understands, not just generates text.
What Real Users Are Saying
A Reddit user built a complete tower defense game autonomously. The model self-debugged compilation errors and iterated on gameplay mechanics. Post got 999+ upvotes on r/LocalLLaMA.
Another report: 100 tokens per second on an M5 Max. No quantization. Full precision. That's the MoE advantage in practice.
More interesting: users are successfully running it at 2-bit quantization. GGUF formats are already circulating. The model is "extremely resistant to quantization" according to early testers.
The caveat? Some users report infinite reasoning loops on complex, multi-step tasks. The model sometimes doesn't know when to stop thinking. It's a known issue with chain-of-thought-heavy MoEs.
The Competitive Landscape
Kimi-K2.6 dropped yesterday with 1T parameters and 32B active. Benchmarks are slightly higher. But you can't run Kimi locally. It's API-only through Together, Novita, and Fireworks.
GLM-5.1 from Zhipu AI beats GPT-5.4 on coding. Also closed API. No weights.
Gemma4-31B and 26B-A4B are Google's entries. The 26B-A4B is MoE too. But Qwen3.6-A3B absolutely dominates on coding benchmarks. Google's models score 52% and 59% on SWE-bench Verified. Qwen3.6-A3B scores 73.4%.
The Qwen3.5-27B dense model is the closest comparison. Same family, similar training data. Qwen3.6-A3B matches its performance while activating 3B parameters instead of 27B. That's the MoE efficiency story in one number.
Why This Matters
Local LLMs have been stuck in a trade-off. You either run a small model with limited capability, or a large model with limited speed.
MoE was supposed to solve this. The theory was clean: route tokens to specialized experts, activate fewer parameters, maintain quality. Practice was messier. Early MoEs were hard to train, harder to quantize, and didn't always beat dense baselines.
Qwen3.6-35B-A3B is the moment the theory finally works at scale. The numbers back it up. The community testing backs it up. The fact that you can quantize it to 2 bits and still get usable outputs backs it up.
Getting Started
The model is live on HuggingFace under Qwen/Qwen3.6-35B-A3B. GGUF variants are already appearing on HuggingFace for llama.cpp users.
For production inference, vLLM supports the architecture out of the box. For local experimentation, Ollama should have it within days.
The Apache 2.0 license means you can fine-tune, distill, and deploy commercially without a lawyer. That's increasingly rare in the model release landscape.
The Bottom Line
If you've been waiting for MoE to deliver on its promises, the wait is over. Qwen3.6-35B-A3B is the first open-weights MoE that beats comparable dense models while running efficiently on consumer hardware. The benchmarks prove it. The community confirms it.
Local agentic coding just got real.