What It Is
Alibaba's Qwen team just dropped the first open-weight variant of Qwen3.6. This isn't another incremental release—it's a 35B parameter MoE model that only activates 3B parameters per inference pass. The architecture is genuinely novel.
Architecture Deep Dive
Key Innovation: Gated DeltaNet + MoE hybrid. 10 blocks of (3x Gated DeltaNet → MoE) → 1x (Gated Attention → MoE). This isn't standard transformer territory.
The model uses:
- 256 total experts, 8 routed + 1 shared per token
- 40 layers with alternating linear and full attention
- 256K native context (extensible to 1M tokens)
- Vision encoder (27 depth, 1152 hidden size) baked in
The Gated DeltaNet component uses 32 heads for V and 16 for QK, each with 128-dim heads. This is linear attention territory—different from the standard KV cache machinery.
Benchmarks: The Numbers That Matter
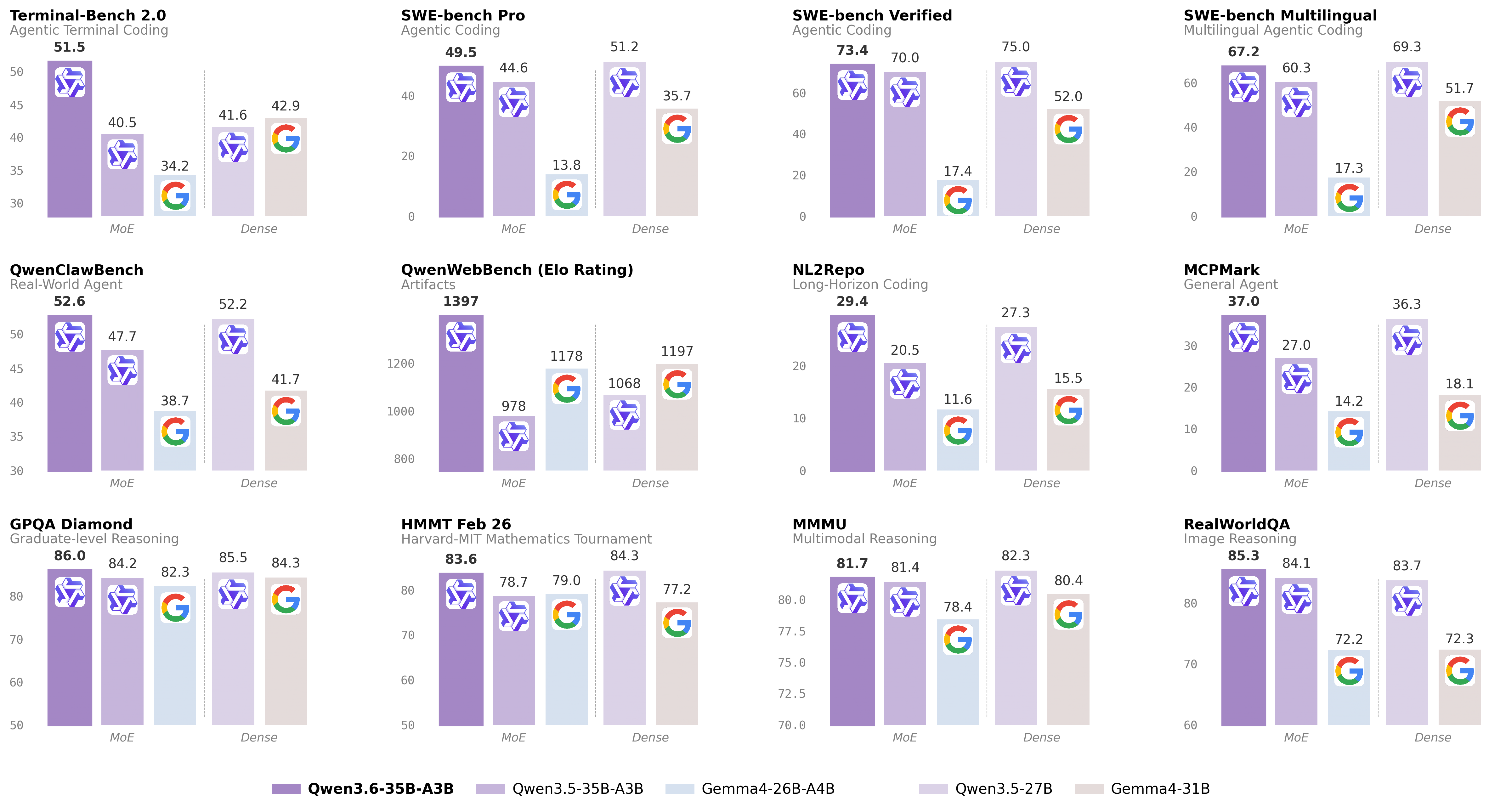
Coding Agent Performance
| Benchmark | Qwen3.5-27B | Qwen3.6-35B-A3B | Gemma4-31B |
|---|---|---|---|
| SWE-bench Verified | 75.0 | 73.4 | 52.0 |
| SWE-bench Multilingual | 69.3 | 67.2 | 51.7 |
| Terminal-Bench 2.0 | 41.6 | 51.5 | 42.9 |
| Claw-Eval Avg | 64.3 | 68.7 | 48.5 |
| NL2Repo | 27.3 | 29.4 | 15.5 |
| QwenWebBench | 1068 | 1397 | 1197 |
Terminal-Bench 2.0: +10 points over Qwen3.5-27B. That's the practical coding metric—the one that tells you if your agent actually works in a shell.
General Agent & Knowledge
| Benchmark | Score |
|---|---|
| MMLU-Pro | 85.2 |
| GPQA | 86.0 |
| AIME26 | 92.7 |
| MCPMark | 37.0 |
| DeepPlanning | 25.9 |
What's New in Qwen3.6
Two features worth noting:
Agentic Coding: Frontend workflows and repository-level reasoning now handled with "greater fluency and precision." The benchmarks back this up—NL2Repo at 29.4 vs 15.5 for Gemma4.
Thinking Preservation: New option to retain reasoning context from historical messages. This reduces overhead in iterative development—you don't lose the chain of thought between turns.
Community Reaction
"A relief to see the Qwen team still publishing open weights, after the kneecapping and departures of Junyang Lin and others." — Hacker News comment
"This is the AI software I actually look forward to seeing. No hype about it being too dangerous to release. No IPO pumping hype. No subscription fees." — Hacker News comment
The HN thread hit 65 points in hours. Users are asking the right questions: How does it compare to Sonnet 4.5? Is it close enough that "free" becomes the right answer?
The MoE Efficiency Claim
35B total, 3B active. That's the MoE promise—you get the capacity of a large model but pay the inference cost of a small one. For local deployment on consumer hardware, this matters.
"I hope the other sizes are coming too (9B for me). Can't fit much context with this on a 36GB mac." — Hacker News user
The reality check: 256K context on a 36GB Mac Studio is tight. Users want smaller variants.
Deployment
Compatible with:
- Hugging Face Transformers (v4.57.1+)
- vLLM
- SGLang
- KTransformers
Qwen-Agent framework recommended for building agent applications. MCP integration supported out of the box.
The Verdict
This is what the open-source AI community actually wants: a genuinely novel architecture, solid coding benchmarks, no hype cycle, Apache 2.0 license. The Terminal-Bench 2.0 jump from 41.6 to 51.5 is the headline number—it's a 23% improvement on practical agent tasks.
For dev shops in banking and healthcare that can't touch public models, this is exactly the right size class. Western players (except Mistral) are mostly ignoring this segment.
Download: HuggingFace