Most multi-agent frameworks are talking past each other.
AutoGen, CrewAI, LangGraph—they all use text-based communication. Agent A generates tokens, Agent B reads them, generates more tokens. It's slow. It's expensive. And it breaks gradient flow during training.
A team from Stanford, UIUC, NVIDIA, and MIT just dropped RecursiveMAS. They asked a simple question: what if agents passed continuous latent representations instead of text?
The answer: +8.3% accuracy, 2.4x faster, 75% fewer tokens.
The Architecture That Changes Everything
The core innovation is RecursiveLink—a two-layer residual projection module.
It does two things:
- Inner link: Lets each agent generate "latent thoughts"—continuous reasoning steps without emitting tokens
- Outer link: Bridges heterogeneous agents (different sizes, different architectures) via cross-model dimension mapping
The math is clean: R(h) = h + W_2 σ(W_1 h) for inner links, plus a linear W_3 for outer links bridging different embedding dimensions.
This creates a unified loop. Agent A's latent state flows to Agent B's input space. Agent B's flows to Agent C. The last agent feeds back to the first. Only the final round produces text output.
Benchmarks That Actually Matter
They tested on 9 datasets across math, science, medicine, search, and code:
| Benchmark | RecursiveMAS | Best Baseline |
|---|---|---|
| MATH500 | 88.0 | 85.8 (Recursive-TextMAS) |
| AIME2025 | 86.7 | 73.3 (multiple) |
| AIME2026 | 86.7 | 76.7 (Full-SFT) |
| GPQA-Diamond | 66.2 | 62.8 (Full-SFT) |
| LiveCodeBench-v6 | 42.9 | 39.8 (TextGrad) |
| MedQA | 79.3 | 77.2 (TextGrad) |
The AIME gains are notable—13+ percentage points over baselines. That's not incremental.
Efficiency Numbers
At recursion depth r=3:
- Inference speedup: 2.4x vs text-based MAS
- Token reduction: 75.6%
- GPU memory during training: 15.29 GB (vs 41.40 GB for full SFT)
- Training cost: $4.27 (vs $9.67 for full SFT)
The token savings hit hard at production scale. If you're running agents at 10M tokens/day, 75% reduction is a $7500/month difference on most API pricing.
Why This Actually Works
The paper proves gradient stability. When token predictions are confident (low entropy), text-based supervised fine-tuning suffers from gradient vanishing. RecursiveLink maintains gradient norm ≈ 1.
This matters because it means you can actually train the system. Not just glue agents together with prompts—optimize the collaboration itself.
Comparison With Existing Frameworks
AutoGen/CrewAI: Text-based dialogue. No built-in optimization. RecursiveMAS treats collaboration as learnable computation.
LangGraph: Graph-based state machines. Explicit state nodes. RecursiveMAS uses continuous latent states.
TextGrad: Uses natural language feedback as gradients. RecursiveMAS uses actual gradients.
LoopLM: Single-model recursion. RecursiveMAS extends recursion to entire multi-agent systems.
The key difference isn't incremental—it's architectural. Existing frameworks orchestrate. RecursiveMAS computes.
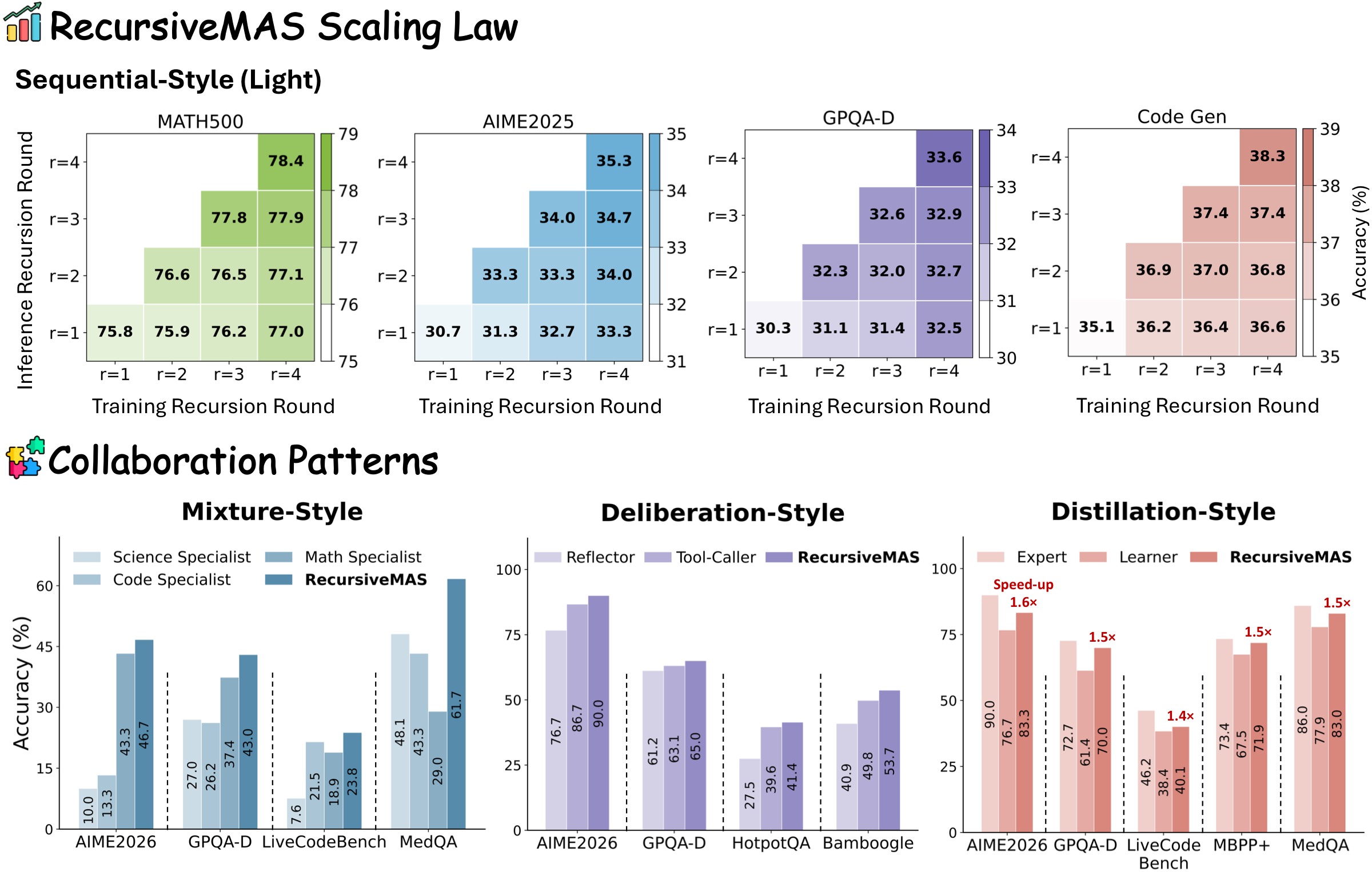
The Four Patterns They Support
- Sequential: Planner → Critic → Solver
- Mixture: Parallel specialists + Summarizer
- Distillation: Expert → Learner
- Deliberation: Reflector ↔ Tool-Caller
Structure-agnostic. Same core mechanism, different collaboration topology.
What's Missing
The paper doesn't compare against reasoning models like DeepSeek-R1. That's a gap.
It's also freshly published (April 28, 2026). Real-world deployment experience doesn't exist yet. The experiments ran on H100/A100 GPUs—smaller setups may see different economics.
The Implications
If this holds up at production scale, it changes the economics of multi-agent systems. Token costs, latency, training feasibility—all shift.
The theoretical contribution (gradient stability proofs) opens a research direction: end-to-end trained multi-agent systems, not just prompted orchestration.
For teams building agent pipelines: the question shifts from "which framework" to "whether text-based communication is even the right layer."