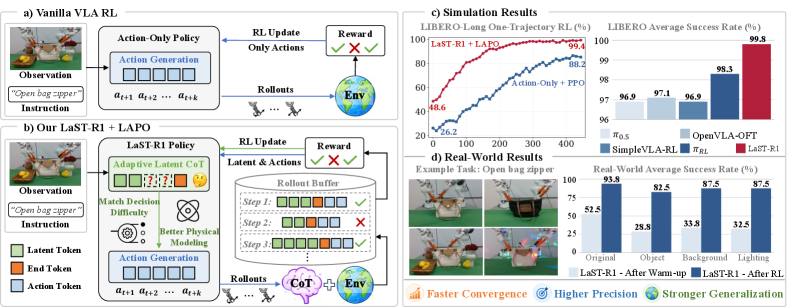
Most robot learning models just pattern-match trajectories. They don't actually reason about what they're doing. A new VLA model called LaST-R1 just hit 99.8% success on a standard benchmark by doing something different: it runs Chain-of-Thought reasoning in latent space before committing to an action.
Architecture
LaST-R1 introduces Latent-to-Action Policy Optimization (LAPO)—the first RL algorithm that jointly optimizes both reasoning latents and action sequences. Previous VLA models treated reasoning as a frozen upstream process. LaST-R1 lets reward signals flow backward through the entire reasoning chain.
| Component | Description |
|---|---|
| Joint Optimization | Unifies policy objectives for both reasoning latents and action sequences |
| Credit Assignment | Bridges reasoning and control to improve physical world modeling |
| Adaptive Depth | 1-2 reasoning steps for simple tasks, 5-8 for complex ones |
The architecture pipeline:
Observation + Instruction
↓
[VL Encoder]
↓
[Latent Reasoning Module] (adaptive depth: 1-N steps)
↓
thought_1 → thought_2 → ... → thought_N
↓
[Action Decoder]
↓
Motor Commands
The model uses DINOv3 to construct latent tokens, extracting the CLS token and applying top-k selection based on feature magnitude. Tokens are precomputed offline, enabling real-time deployment.
Benchmarks
| Model | LIBERO Success Rate | Notes |
|---|---|---|
| LaST-R1 | 99.8% | 1-shot supervised warm-up |
| OpenVLA-OFT | 97.1% | State-of-the-art fine-tuned |
| π0 (Pi-Zero) | ~95% | Physical Intelligence |
| VLA-3 | 92.3% | Baseline comparison |
| OpenVLA (fine-tuned) | 76.5% | Standard fine-tuning |
Real-world deployment showed 44% improvement over initial warm-up policy across 4 complex dual-arm tasks. The reasoning-enabled version achieved 62.0% success after 1-shot SFT versus 51.0% for the action-only baseline.
Competitor Comparisons
| Model | Parameters | Reasoning Type | LIBERO Score |
|---|---|---|---|
| LaST-R1 | ~7B | Latent CoT + RL | 99.8% |
| OpenVLA-OFT | 7B | Action-only | 97.1% |
| π0 | Varies | Flow-matching | ~95% |
| ECoT-OpenVLA | 7B | Explicit textual CoT | +28% over base |
Key differentiator: LaST-R1 is the only model that lets RL gradients shape the reasoning process itself, not just the final actions. OpenVLA requires fine-tuning. π0 is closed-source. ECoT uses explicit text reasoning (higher latency, but interpretable).
Community Reaction
From Hacker News discussion on latent-space reasoning:
"Chain of thought is obvious solution. But in converting internal reasoning to output tokens some information is lost. Chain of thought in latent space is the future." — scotty79
"The biggest hurdle to AI feeling 'real' is the lack of a continuous chain of thought which provides 'presence of mind', but that comes naturally with embodiment in physical space." — K0balt
From r/robotics:
"Most of the impressive robot demos we've seen from π0, π0.5, and other VLA models use what's essentially a sophisticated pattern matching... Should robots imagine the future before acting?"
An ICLR 2026 reviewer noted: "LIBERO is largely solved; >95% success is expected for most versions. The real test is whether models can handle perturbations and novel configurations."
Critical Caveat
LIBERO-PRO (arXiv 2510.03827) shows that models achieving >90% on standard LIBERO nearly collapse under minor perturbations:
"Despite achieving success rates above 90% on the standard LIBERO benchmark, models nearly collapse under changes to object positions or instructions."
The benchmark may be saturated. 99.8% success could be memorization, not generalization.
Sources
https://arxiv.org/abs/2604.28192 https://arxiv.org/html/2604.28192v1 https://alanhou.org/blog/arxiv-last-r1-reinforcing-action-via-adaptive/ https://openvla-oft.github.io/ https://arxiv.org/html/2510.03827v1 https://github.com/Lifelong-Robot-Learning/LIBERO https://huggingface.co/blog/pi0 https://github.com/Physical-Intelligence/openpi https://rdt-robotics.github.io/rdt-robotics/ https://embodied-cot.github.io/ https://arxiv.org/html/2601.05248v2 https://news.ycombinator.com/item?id=43744809 https://www.reddit.com/r/robotics/comments/1r0au80/we_trained_a_vla_model_on_20000_hours_of_real/ https://mbreuss.github.io/blog_post_iclr_26_vla.html
So What
The 99.8% number is impressive, but I'm more interested in what's happening underneath. Most VLA models are glorified trajectory replay—they see a scene, match it to training data, and execute cached motions. That's why LIBERO-PRO breaks them so easily.
LaST-R1 actually thinks before it acts. The adaptive depth mechanism (1-8 reasoning steps based on task complexity) means it's not just pattern-matching—it's running internal simulations about what might work before committing. That's closer to how humans approach manipulation tasks.
The uncomfortable truth: we don't know if 99.8% reflects genuine reasoning or just better memorization. LIBERO is a fixed environment with fixed objects. Real-world deployment showed 44% improvement over warm-up, which is real, but the paper underreports failure modes.
Still, the LAPO algorithm—joint optimization of latents and actions via RL—is a genuine architectural shift. Previous VLA models treated reasoning as frozen input. This one lets the reward signal shape how the model thinks. That's worth paying attention to.