Traditional TTS models have been stuck in a trap. VALL-E, CosyVoice, Fish-Speech—they all use discrete speech tokens. That quantization step irreversibly discards fine-grained acoustic details. You get speech that sounds right but lacks the nuance, the texture, the human quality.
OpenBMB's VoxCPM2 just broke the mold. It's tokenizer-free.
The Architecture That Matters
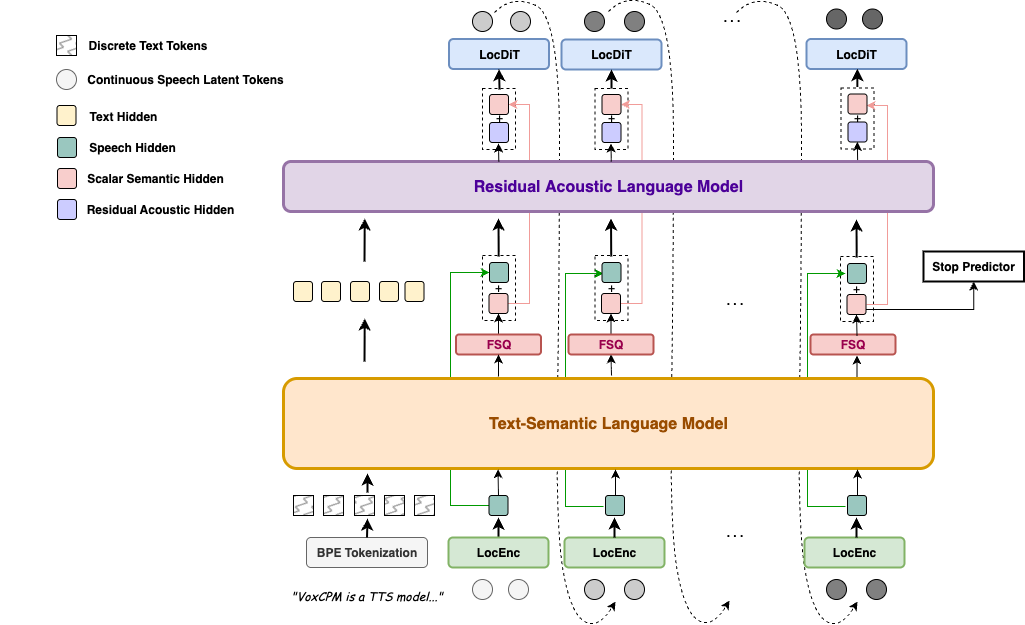
VoxCPM2 resolves what researchers call the "expressivity-stability trade-off" through hierarchical semantic-acoustic modeling. The flow is clean:
LocEnc → TSLM → FSQ → RALM → LocDiT
TSLM (Text-Semantic Language Model) handles high-level linguistic structure and prosody planning. Built on MiniCPM-4 backbone for contextual understanding.
FSQ (Finite Scalar Quantization) is the magic. Differentiable quantization that creates a "semi-discrete speech skeleton"—stabilizing generation without discarding acoustic details.
RALM (Residual Acoustic Language Model) recovers what quantization normally kills: fine-grained acoustic detail.
LocDiT (Local Diffusion Transformer) renders 48kHz studio-quality audio with built-in super-resolution via AudioVAE V2.
No external upsampler needed. No discrete token bottleneck. End-to-end trainable.
Benchmarks: Where It Actually Wins
On Seed-TTS-eval, VoxCPM2 achieves:
- English WER: 1.84% (better than F5-TTS, CosyVoice2)
- Chinese CER: 0.97% (competitive with Fish Audio S2)
- Similarity: 75.3% EN, 79.5% ZH (among the highest for open-source)
On MiniMax-Multilingual-Test, VoxCPM2 dominates similarity across languages:
- English: 85.4% (vs ElevenLabs 61.3%)
- Turkish: 87.1% (vs ElevenLabs 59.6%)
- Finnish: 89.0% (vs ElevenLabs 75.9%)
That's not close. VoxCPM2 beats ElevenLabs by 15-27 points on similarity.
The InstructTTSEval results for Voice Design are equally striking:
- APS: 84.2 (beat Qwen3TTS-VD, Hume)
- DSD: 83.2
- RP: 71.4
30 Languages + 9 Chinese Dialects
Arabic, Burmese, Chinese, Danish, Dutch, English, Finnish, French, German, Greek, Hebrew, Hindi, Indonesian, Italian, Japanese, Khmer, Korean, Lao, Malay, Norwegian, Polish, Portuguese, Russian, Spanish, Swahili, Swedish, Tagalog, Thai, Turkish, Vietnamese.
Plus dialects: 四川话, 粤语, 吴语, 东北话, 河南话, 陕西话, 山东话, 天津话, 闽南话.
Three Modes of Generation
Voice Design: Create brand-new voices from natural-language descriptions. No reference audio needed.
(A young woman, gentle and sweet voice)Hello!produces exactly that.Controllable Cloning: Clone a voice but control style independently.
(slightly faster, cheerful tone)This is cloned.preserves timbre while allowing expression manipulation.Ultimate Cloning: Full nuance preservation. Reference audio + exact transcript reproduces timbre, rhythm, emotion, everything.
What Reddit Users Are Saying
r/LocalLLaMA (107 upvotes, 98% ratio): Users praise cross-lingual capability and 30-language coverage. One comment: "OpenBMB certainly seems to understand how their demographic intends to use these models"—referencing the anime/character voice creation use cases.
r/StableDiffusion: ComfyUI integration with LoRA training. User: "100% faithfully recreate voices with this model and a custom trained LoRA."
But the criticism is real too: "every generation outputs slightly different voice even with reference audio"—similarity consistency isn't perfect yet. Style instructions: "really unreliable—whisper to ear vs alien summoning with same instruction."
Real-Time Performance
RTF ~0.3 on RTX 4090. With Nano-vLLM acceleration: ~0.13. That's under 10% of audio duration for inference. Streaming-capable via LocDiT's design.
The Competition
| Model | Tokenizer-Free | Languages | Voice Design | Params |
|---|---|---|---|---|
| VoxCPM2 | Yes | 30 | Yes | 2B |
| VALL-E | No | 1 | No | - |
| CosyVoice | No | 2 | No | 1.5B |
| F5-TTS | No | 2 | No | 0.3B |
| Qwen3-TTS | No | Multi | Yes | 1.7B |
Only VoxCPM2 combines tokenizer-free architecture with voice design capability. Qwen3-TTS has voice design but uses discrete tokens.
How to Run It
pip install voxcpm
from voxcpm import VoxCPM
model = VoxCPM.from_pretrained("openbmb/VoxCPM2")
wav = model.generate(
text="(A young woman, gentle voice)Hello, welcome!",
cfg_value=2.0,
)
Apache-2.0 licensed. Commercial-ready.
The Bottom Line
Tokenizer-free isn't just a technical novelty—it solves the fundamental problem that discrete-token TTS can't. VoxCPM2's semi-discrete approach preserves what quantization kills. The benchmarks prove it: highest similarity scores among open-source models, competitive WER/CER, and voice design that actually works.
If you're building voice applications, this is the model to test first.
https://github.com/OpenBMB/VoxCPM https://huggingface.co/openbmb/VoxCPM2 https://arxiv.org/abs/2509.24650