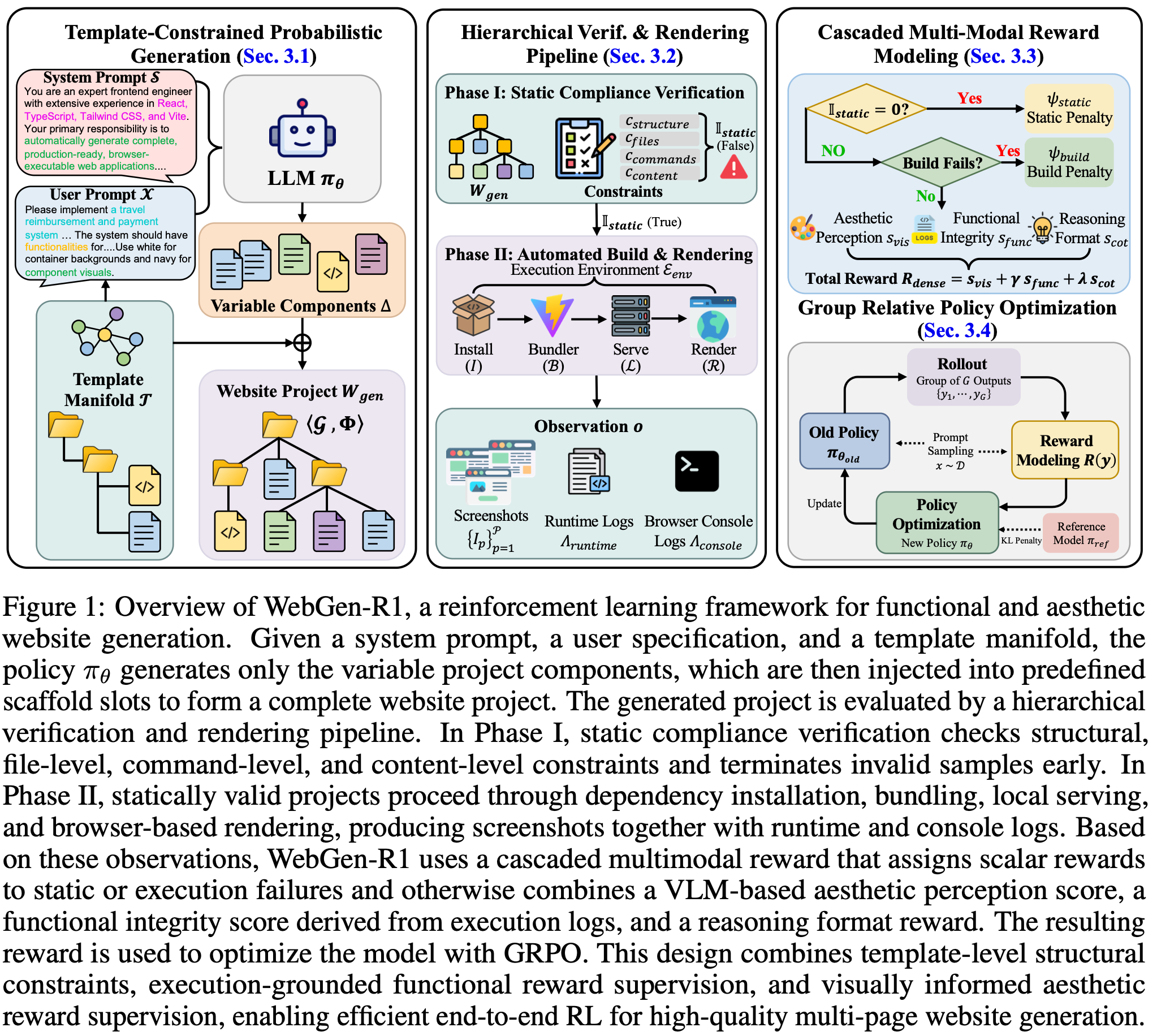
Most code generation models excel at single-file scripts but collapse when you ask them to build a multi-page website. The context windows get fragmented, dependencies break, and you end up with a pile of disconnected components that don't actually run.
A team from HKUST Guangzhou, Alibaba's Tongyi Lab, and Ant Group just dropped WebGen-R1—a 7B model trained with reinforcement learning that achieves DeepSeek-R1 (671B) level performance on full website generation. The key insight isn't bigger parameters. It's smarter rewards.
The Scaffold-Driven Approach
WebGen-R1 starts with a fixed template manifold (vite-react-typescript-starter). Instead of generating everything from scratch, the model fills predefined scaffold slots—routing logic, component structure, styling. This guarantees the output builds and renders.
The template approach eliminates brittle dependency chains. You get a project that actually compiles, not just syntactically correct files that fail at runtime.
Cascaded Multimodal Rewards
The real innovation is the reward system. WebGen-R1 uses a hierarchical reward cascade:
- Static compliance checks first (structure, file presence, content rules)
- Build verification second (dependency resolution, bundling)
- Dense aesthetic/functional rewards only if the project actually renders
The dense reward formula combines three signals: visual aesthetic score (VLM-assigned, 0-5 scale), functional integrity (binary: no console errors), and reasoning format quality. If the build fails, the model gets a simpler static reward—no wasting compute on evaluating broken output.
Benchmarks That Matter
On WebGen-Bench (101 samples, 647 test cases), WebGen-R1-7B achieved:
- Functional Success Rate: 29.21% — matching DeepSeek-R1-671B at 30.25%
- Valid Render Ratio: 95.89% — the highest among all tested models (DeepSeek-R1: 42.86%, Claude-3.7-Sonnet: 84%, GPT-5: 90.43%)
- Aesthetic Alignment Score: 3.94 — best among all models, beating Claude-3.7-Sonnet (3.90)
The 7B model outperforms every open-source model up to 72B in functional success. It beats all proprietary models in valid render ratio and aesthetic alignment.
Training Details
- Base model: Qwen2.5-Coder-7B-Instruct
- SFT warm-up: 600 instances distilled from GPT-4.1
- RL fine-tuning: 400 GRPO steps, 8× H100 GPUs
- Group size: 16 samples per gradient update
- Training framework: TRL + vLLM acceleration
What's Missing
The GitHub repo (11 stars as of April 26) doesn't have released model weights yet. There's an open issue requesting Hugging Face release. Without the weights, you can't actually use this yet.
The paper also notes limitations on newer design trends—the WebDev Arena evaluation showed occasional misses on edge-case aesthetics.
Why This Matters
WebGen-R1 demonstrates that RL with domain-specific rewards can compress 96x model size difference into comparable results. That's the real story: structured generation + cascaded rewards > brute-force scaling.
For teams building code generation pipelines, this is a signal that investing in reward engineering might yield better ROI than chasing larger foundation models.
The paper: https://arxiv.org/abs/2604.20398 GitHub: https://github.com/juyongjiang/WebGen-R1